数据怎么变成钱的。左边这个广告位投放的吉列剃须刀的广告,这个广告位卖一万块钱,是流量的价值,我每天来了十万人,这十万人看到这个广告,你就得给我一万块钱。吉列是主要面对男性的广告主,我只给男性用户投吉列广告,省出来的用户都是女性用户,我找一个化妆品的广告投给女性用户,我找每一个广告主各收六千块钱。对媒体来说,投入产出比也提高了,我收到了一万两千块钱。我特别要强调,多出来的两千块钱是什么,这两千块钱就是数据变现的价值。你知道了每一个人是男是女,在原来一万块钱基础上可以凭空多挣两千块钱。仅仅知道一个性别就可以多挣两千,你要知道更多这个人的信息和购物偏好,你显然可以挣更多的钱,这些钱都是数据变现带来的钱。 ——刘鹏
投标(Bidding)
竞价系统,即广告客户选择愿意为广告点击支付的最高出价金额。出价越高,展示位置就越好。你可以使用以下三种出价方式:CPC、CPM或CPE。
-
**CPC:**Cost Per Click即每次点击费用,是指为广告的每次点击所支付的费用。
-
**CPM:**Cost Per Mille即每千次展示费用,当广告向一千人展示时需要支付的费用。
-
**CPE:**Cost Per Engagement即每次互动费用,当用户对广告采取预定操作时需要支付的费用。
点击率(CTR:Click-Through Rate)
CTR是指广告获得的点击次数占观看次数的比例。点击率越高,表示广告质量越高,该广告就可以匹配搜索意图并定位相关的关键字。
关键词
当用户在搜索框中输入关键字查询时,显示与搜索者意图相符的一系列结果。
关键字是与搜索者的需求相符并能满足其查询条件的词或短语。你可以根据显示广告的查询选择关键字。例如,输入“如何清除鞋上的口香糖”后,将看到“鞋上的口香糖”和“清洁鞋”等搜索结果。
**否定关键字(Negative Keywords)**是指你不想为其排名的关键字词的列表。 Google会将这些关键字从你的出价中撤出。通常情况下,这些关键词与你想要的关键词还是有一定联系的,但却超出了你所能提供或想要的排名范围。
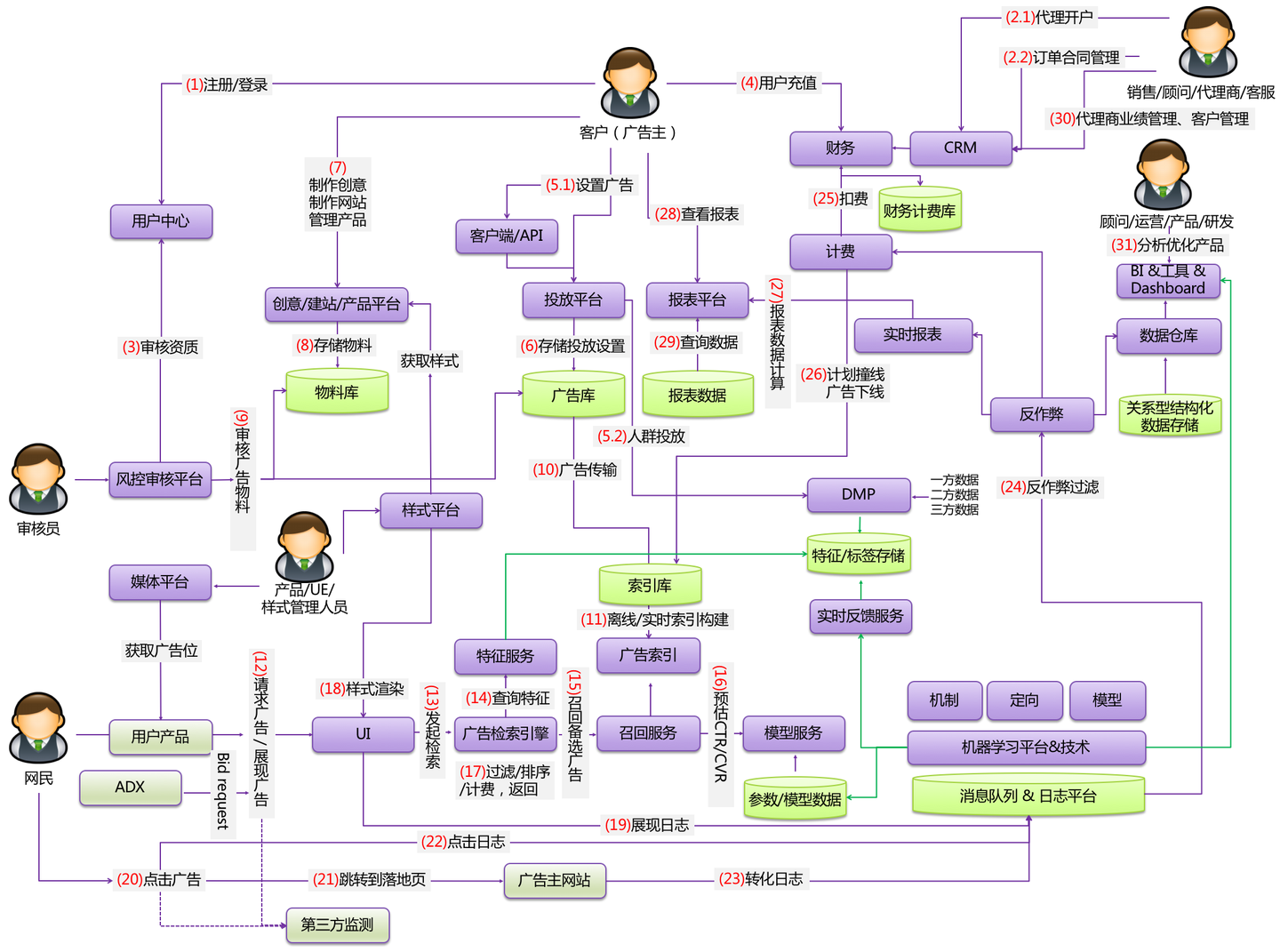
在推荐系统中一般会分为召回和排序两个阶段:
召回的目标是从千万级甚至亿级的候选中召回几千个item,召回一般由多路组成,每一路会有不同的侧重点(优化目标),如在广告中成熟期广告和冷启动广告分为两路召回(如果广告比较多,还可能分冷热广告分别召回)。在推荐系统,不同路可能代表了不同的优化目标,如喜欢、关注、观看时长、评论这些都可以分不同的路召回。
目前召回常用的方法有:协同过滤、FM、FFM、图模型、双塔模型、还有YouTube在2017年论文中提出的DNN模型、字节的Deep Retrieval算法等
在工业届,常常会用FM、双塔模型等先学习user embedding、和 item embedding,然后用ball tree、fast ball tree 等近似最近邻算法进行检索,加快效率
召回的目的在于减少候选的数量(尽量控制在1000以内),方便后续排序环节使用复杂模型精准排序;因为在短时间内评估海量候选,所以召回的关键点是个快字,受限与此与排序相比,召回的算法模型相对简单,使用的特征比较少。
业界普遍采用的方式是多路召回,即从多个维度出发在海量库里把相关度高的候选尽可能找出来。
多路同时召回是出于多方面的考虑:
- 多样性,从不同维度出发去找到相关的候选;
- 鲁棒性,即使一路召回出现问题,其他召回通路也会正常运行不至于阻塞主流程;
- 可解释与灵活性,每一路从单独维度出发可以很好解释召回的逻辑,如果效果不理想调整起来复杂度低更加灵活。
在某一路召回时选好方向确定对应的打分函数,之后进行打分、排序、截断召回topN,各路召回之间彼此独立,胜出的候选之间不具有可比性。
召回主要从用户(U)、上下文(C)、搜索词(Q)、广告(A)几个大方向出发,细化维度可以结合实际业务场景,可以基于上下文标题/描述/分类/标签/图片、用户基础统计信息/兴趣标签/历史行为、检索词、基于物品的协同过滤,处理的信息是多模态的包括文字、图片、视频等。
具体召回匹配时有两种思路:
- 基于标签/关键词的文本硬匹配,如广告定向中的地域、性别,要么匹配,要么不匹配,扩展性及灵活度差一些;
- 基于向量的语义软匹配。选择有效的原始特征进行embedding嵌入向量空间,通过双塔模型学习获得用户、广告的向量表示,利用点积、余弦相似度或者欧氏距离等方式计算向量相关度,类似Youtube的推荐双塔和微软的DSSM;既可以改变阈值调整召回数量又能满足性能需求,是当前召回的主流形式。
召回不像排序阶段直接影响业务指标,经过粗排精排等环节作用后对最终结果的影响已经很小,对质量衡量难度相对较大,可以从两个方面出发尝试评估:
- 独特性,某路召回结果的不可替代或者与其他通路的重复度,重复度越高该路召回的价值越小;
- 转化效果,召回结果的后续表现,如精排后的排名或者被曝光后用户是否点击,效果越好价值越高。
排序阶段就是把召回的结果进行排序,把top k(k 一般都是个位数)结果作为推荐系统最终的输出。
如果说召回是提供可能性,则排序是提供确定性:把最合适的候选找出来推给用户。
排序细化可以分为粗排、精排、重排。
- 粗排是召回阶段返回的候选数量还是太多,精排直接处理性能上不能满足,粗排用简单模型再做一次过滤减少数量,是个可选环节;
- 精排是整个排序的关键,是各路模型的主战场,也是我们讨论的主角。
- 重排则是出于业务考虑,对精排后的结果进行处理:多样性、频控、类别控制、特定结果提权等;
把排序阶段分为粗排和精排,其实就是生成环境中成本和结果的一个平衡。进入排序阶段的候选集一般确实只有几千个,但是对于抖音、YouTube这种量级的应用来说,他们request是非常多的,依然不能上太复杂的模型和特征。
因此把排序分为粗排和精排:
粗排漏斗一般是: 几千 -> 几百
精排漏斗一般是:几百 -> 几个
这样精排可以把模型和特征做到极致,可以达到非常高的精度
召回是漏斗的最上游,可以说是决定了推荐系统的上限
召回的目标是召回用户可能感兴趣的 item,会考虑多方面的因素
粗排是对召回的结果进行排序,top k 送入精排,常用的有两种建模方式:
-
独立建模,如在在广告推荐中,粗排也是优化ecpm,在推荐中也是优化Finish、Staytime等
-
对齐精排,用 leaning to rank 等方法去学习精排的序
如果说召回决定了推荐系统的上线的话,那么可以说样本的构造决定了模型的上限
先看召回阶段:
正样本一般选择用户有正反馈的样本,如ctr中用户点击了的作为正样本,like中用户点了喜欢的作为正样本
但是负样本该怎么选呢?
最简单的方法就是把send给用户后,用户没有正反馈的样本作为负样本。但是这样会带来一个问题,那就是召回模型在training和serving面临的样本分布是不一样的,违反了机器学习的基本原则。
具体的来说就是,真正被send给用户的item只占所有item非常小的一部分,召回模型在serving时会面临很多它以前从来没有见过的样本,召回模型在这些样本上会很难区分
怎么解决这个问题呢?
通常的方法就是从召回的池子中进行随机采样,具体做法待补充
粗排的基本目标一般是对其精排,所以可以把精排的top k 个样本作为正样本,然后从精排中其它样本中随机采样,作为负样本
粗排对其精排本身没有太大问题,但是这里也有一个ee(exploit-explore)问题,如果粗排完全对其精排的话,可能会导致模型探索不足,为了缓解这个问题,我们可以适当补充一些进入召回但是没有进精排的样本作为负样本
CRT
roi

- 《广告系列:召回与排序》http://www.woshipm.com/pd/4443378.html