
在线性结构中,按照顺序一个一个地看到所有的元素,称为线性遍历。在非线性结构中,由于元素之间的组织方式变得复杂,就有了不同的遍历行为。其中最常见的遍历有:深度优先遍历(Depth-First-Search)和广度优先遍历(Breadth-First-Search)。它们的思想非常简单,但是在算法的世界里发挥着巨大的作用。
「一条路走到底,不撞南墙不回头」是对「深度优先遍历」的最直观描述。
说明:
- 深度优先遍历只要前面有可以走的路,就会一直向前走,直到无路可走才会回头;
- 「无路可走」有两种情况:① 遇到了墙;② 遇到了已经走过的路;
- 在「无路可走」的时候,沿着原路返回,直到回到了还有未走过的路的路口,尝试继续走没有走过的路径;
- 有一些路径没有走到,这是因为找到了出口,程序就停止了;
- 「深度优先遍历」也叫「深度优先搜索」,遍历是行为的描述,搜索是目的(用途);
- 遍历不是很深奥的事情,把 所有 可能的情况都看一遍,才能说「找到了目标元素」或者「没找到目标元素」。遍历也称为 穷举,穷举的思想在人类看来虽然很不起眼,但借助 计算机强大的计算能力,穷举可以帮助我们解决很多专业领域知识不能解决的问题。
「遍历」和「搜索」可以看作是两个等价概念,通过遍历 所有 的可能的情况达到搜索的目的。遍历是手段,搜索是目的。因此「深度优先遍历」也叫「深度优先搜索」。
我们以「二叉树」的深度优先遍历为例,向大家介绍树的深度优先遍历。
二叉树的深度优先遍历从「根结点」开始,依次 「递归地」 遍历「左子树」的所有结点和「右子树」的所有结点。
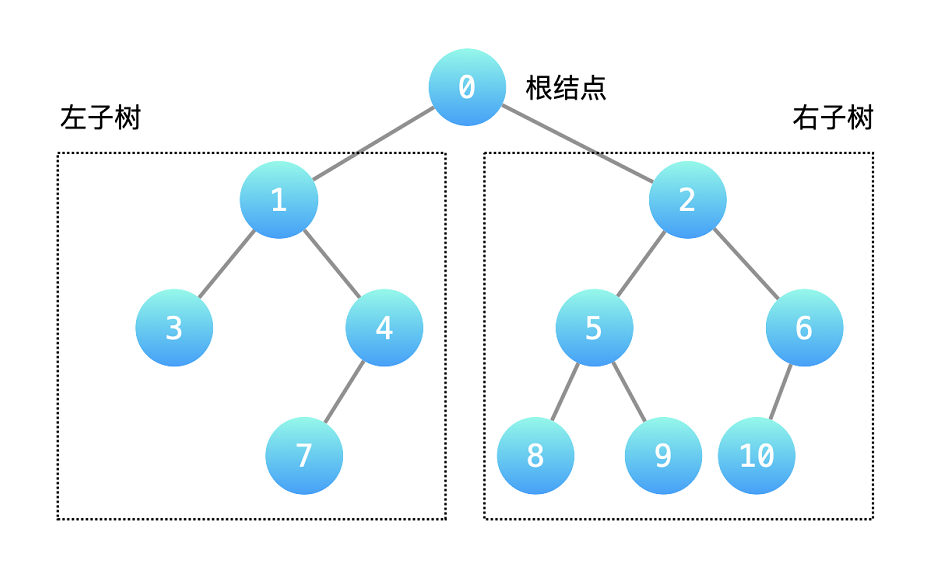
事实上,「根结点 → 右子树 → 左子树」也是一种深度优先遍历的方式,为了符合人们「先左再右」的习惯。如果没有特别说明,树的深度优先遍历默认都按照 「根结点 → 左子树 → 右子树」 的方式进行。
二叉树深度优先遍历的递归终止条件:遍历完一棵树的 所有 叶子结点,等价于遍历到 空结点。
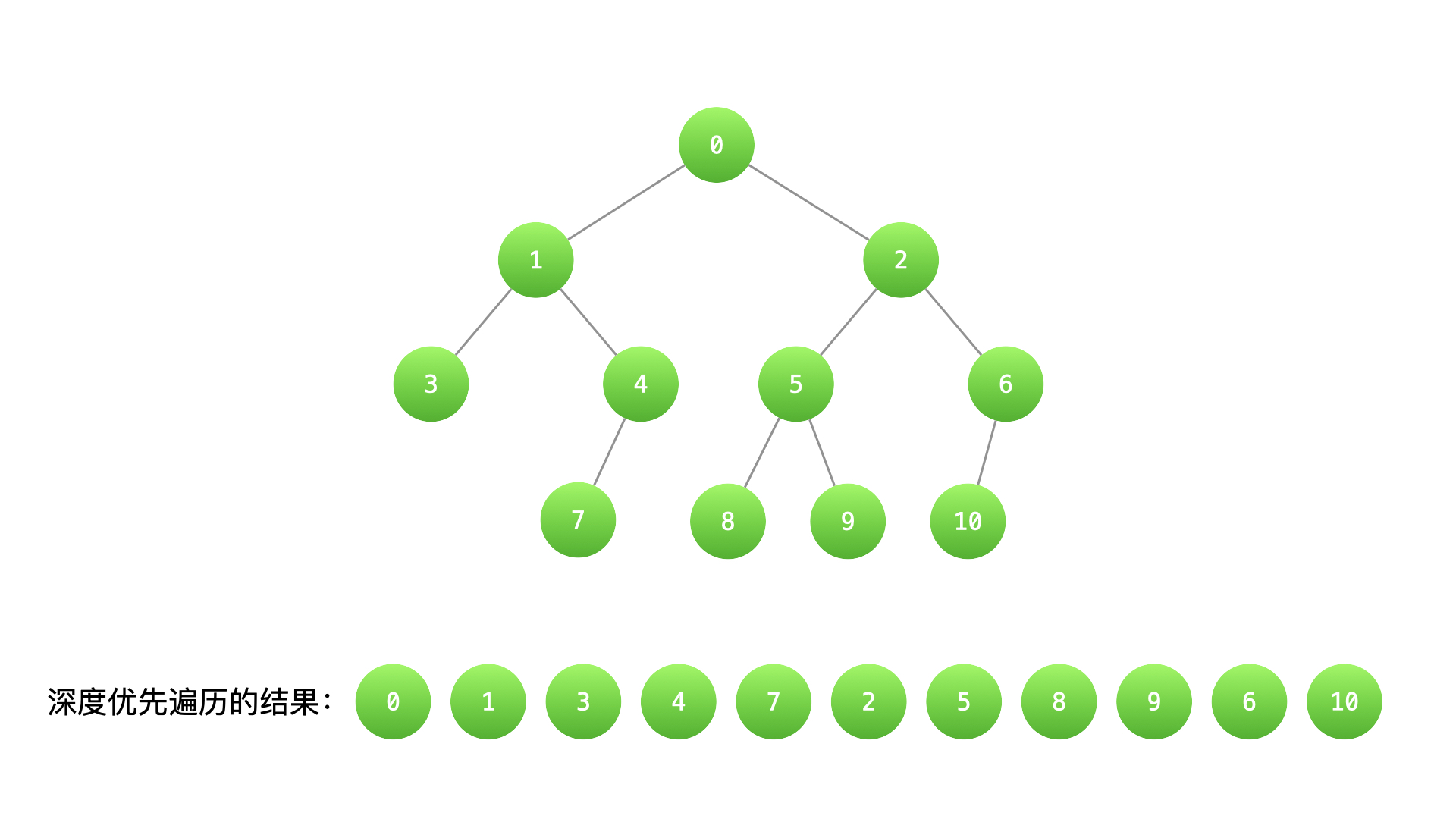
二叉树的深度优先遍历还可以分为:前序遍历、中序遍历和后序遍历。
- 前序遍历
对于任意一棵子树,先输出根结点,再递归输出左子树的 所有 结点、最后递归输出右子树的 所有 结点。上图前序遍历的结果就是深度优先遍历的结果:[0、1、3、4、7、2、5、8、9、6、10]。
- 中序遍历
对于任意一棵子树,先递归输出左子树的 所有 结点,然后输出根结点,最后递归输出右子树的 所有 结点。上图中序遍历的结果是:[3、1、7、4、0、8、5、9、2、10、6]。
- 后序遍历(重要) 对于任意一棵子树,总是先递归输出左子树的 所有 结点,然后递归输出右子树的 所有 结点,最后输出根结点。后序遍历体现的思想是:先必需得到左右子树的结果,才能得到当前子树的结果,这一点在解决一些问题的过程中非常有用。上图后序遍历的结果是:[3、7、4、1、8、9、5、10、6、2、0]。
友情提示:后序遍历是非常重要的遍历方式,解决很多树的问题都采用了后序遍历的思想,请大家务必重点理解「后序遍历」一层一层向上传递信息的遍历方式。并在做题的过程中仔细体会「后序遍历」思想的应用。
- 为什么前、中、后序遍历都是深度优先遍历
可以把树的深度优先遍历想象成一只蚂蚁,从根结点绕着树的外延走一圈。每一个结点的外延按照下图分成三个部分:前序遍历是第一部分,中序遍历是第二部分,后序遍历是第三部分。
只看结点的第一部分(红色区域),深度优先遍历到的结点顺序就是「前序遍历」的顺序

只看结点的第二部分(黄色区域),深度优先遍历到的结点顺序就是「中序遍历」的顺序

只看结点的第三部分(绿色区域),深度优先遍历到的结点顺序就是「后序遍历」的顺序

- 重要性质
根据定义不难得到以下性质。
- 性质 1:二叉树的 前序遍历 序列,根结点一定是 最先 访问到的结点;
- 性质 2:二叉树的 后序遍历 序列,根结点一定是 最后 访问到的结点;
- 性质 3:根结点把二叉树的 中序遍历 序列划分成两个部分,第一部分的所有结点构成了根结点的左子树,第二部分的所有结点构成了根结点的右子树。
友情提示:根据这些性质,可以完成「力扣」第 105 题、第 106 题,这两道问题是面试高频问题,请大家务必掌握。
深度优先遍历有「回头」的过程,在树中由于不存在「环」(回路),对于每一个结点来说,每一个结点只会被递归处理一次。而「图」中由于存在「环」(回路),就需要 记录已经被递归处理的结点(通常使用布尔数组或者哈希表),以免结点被重复遍历到。
下面这些练习可能是大家在入门「树」这个专题的过程中做过的问题,以前我们在做这些问题的时候可以总结为:树的问题可以递归求解。现在我们可以用「深度优先遍历」的思想,特别是「后序遍历」的思想重新看待这些问题。
请大家通过这些问题体会 「如何设计递归函数的返回值」 帮助我们解决问题。并理解这些简单的问题其实都是「深度优先遍历」的思想中「后序遍历」思想的体现,真正程序在执行的时候,是通过「一层一层向上汇报」的方式,最终在根结点汇总整棵树遍历的结果。
- 完成「力扣」第 104 题:二叉树的最大深度(简单):设计递归函数的返回值;
- 完成「力扣」第 111 题:二叉树的最小深度(简单):设计递归函数的返回值;
- 完成「力扣」第 112 题:路径总和(简单):设计递归函数的返回值;
- 完成「力扣」第 226 题:翻转二叉树(简单):前中后序遍历、广度优先遍历均可,中序遍历有一个小小的坑;
- 完成「力扣」第 100 题:相同的树(简单):设计递归函数的返回值;
- 完成「力扣」第 101 题:对称二叉树(简单):设计递归函数的返回值;
- 完成「力扣」第 129 题:求根到叶子节点数字之和(中等):设计递归函数的返回值。
- 完成「力扣」第 236 题:二叉树的最近公共祖先(中等):使用后序遍历的典型问题。
请大家完成下面这些树中的问题,加深对前序遍历序列、中序遍历序列、后序遍历序列的理解。
-
完成「力扣」第 105 题:从前序与中序遍历序列构造二叉树(中等);
-
完成「力扣」第 106 题:从中序与后序遍历序列构造二叉树(中等);
-
完成「力扣」第 1008 题:前序遍历构造二叉搜索树(中等);
-
完成「力扣」第 1028 题:从先序遍历还原二叉树(困难)。
友情提示:需要用到后序遍历思想的一些经典问题,这些问题可能有一些难度,可以不用急于完成。先做后面的问题,见多了类似的问题以后,慢慢理解「后序遍历」一层一层向上汇报,在根结点汇总的遍历思想。
- 遍历可以用于搜索,思想是穷举,遍历是实现搜索的手段;
- 树的「前、中、后」序遍历都是深度优先遍历;
- 树的后序遍历很重要;
- 由于图中存在环(回路),图的深度优先遍历需要记录已经访问过的结点,以避免重复访问;
- 遍历是一种简单、朴素但是很重要的算法思想,很多树和图的问题就是在树和图上执行一次遍历,在遍历的过程中记录有用的信息,得到需要结果,区别在于为了解决不同的问题,在遍历的时候传递了不同的 与问题相关 的数据。

在深度优先遍历的过程中,需要将 当前遍历到的结点 的相邻结点 暂时保存 起来,以便在回退的时候可以继续访问它们。遍历到的结点的顺序呈现「后进先出」的特点,因此 深度优先遍历可以通过「栈」实现。
再者,深度优先遍历有明显的递归结构。我们知道支持递归实现的数据结构也是栈。因此实现深度优先遍历有以下两种方式:
- 编写递归方法;
- 编写栈,通过迭代的方式实现。
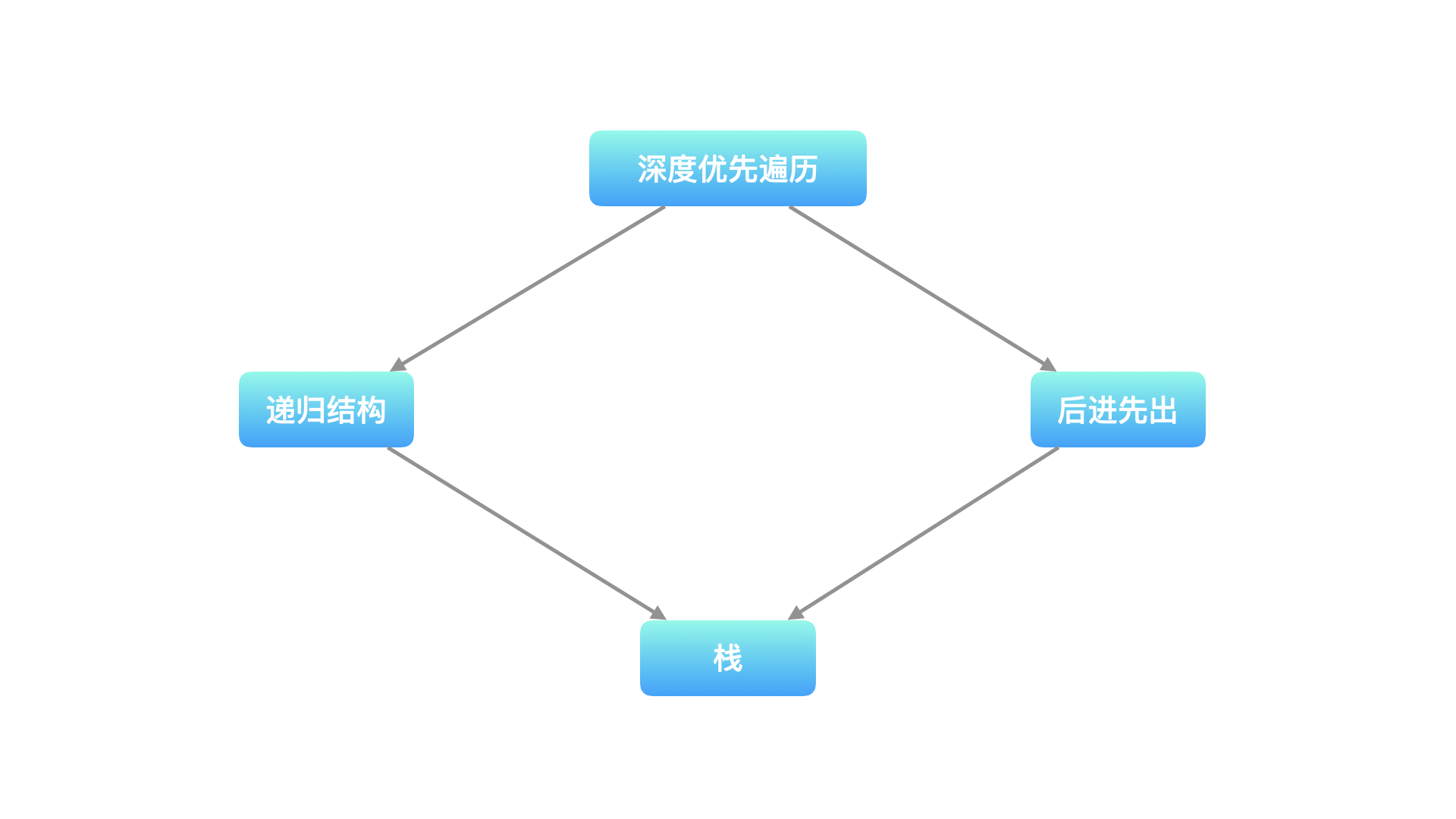
我们通过例题的方式向大家展现一种使用栈模拟的二叉树深度优先遍历的过程。但是要向大家说的是:
- 并不是所有的递归(深度优先遍历)的问题都可以很方便地使用「栈」实现,了解非递归实现可以作为编程练习;
- 虽然「递归调用」在一些编程语言中会造成系统资源开销,性能不如非递归好,还有可能造成「栈溢出」的风险,但是 在工程实践 中,递归方法的可读性更强,更易于理解和以后的维护,因此没有必要苛求必需要将递归方法转换成为非递归实现。
例 1:「力扣」第 144 题:二叉树的前序遍历(简单)
思路分析:递归方法相信大家都会。这里介绍使用栈模拟递归的过程。
对于二叉树的遍历,每一个结点有两种处理方式:
- 输出该结点;
- 递归处理该结点。
我们可以在结点存入栈的时候附加一个「指令信息」,ADDTORESULT 表示输出该结点(添加到结果集),GO 表示递归处理该结点。在栈顶元素的弹出的时候,读取「指令信息」,遇到 GO 的时候,就将当前结点的左、右孩子结点按照「前序遍历」(根 -> 左 -> 右)的「倒序」的方式压入栈中。
「倒序」是因为栈处理元素的顺序是「后进先出」,弹栈的时候才会按照我们想要的顺序输出到结果集。
读者可以结合下面的参考代码理解这种使用「栈」模拟了递归(深度优先遍历)的思想。
注意:
使用栈模拟递归实现的方式并不唯一,这里介绍的栈模拟的方法可以迁移到「力扣」第 94 题(二叉树的中序遍历)和「力扣」第 145 题(二叉树的后序遍历),例 2 和例 3 我们不再过多描述; 感兴趣的朋友还可以参考这些问题的官方题解了解更多使用栈模拟深度优先遍历的实现。
参考代码 1:递归
public class Solution {
public List<Integer> preorderTraversal(TreeNode root) {
List<Integer> res = new ArrayList<>();
dfs(root, res);
return res;
}
private void dfs(TreeNode treeNode, List<Integer> res) {
if (treeNode == null) {
return;
}
res.add(treeNode.val);
dfs(treeNode.left, res);
dfs(treeNode.right, res);
}
}复杂度分析:
时间复杂度:O(N),这里 NN 为二叉树的结点总数; 空间复杂度:O(N),栈的深度为需要使用的空间的大小,极端情况下,树成为一个链表的时候,栈的深度达到最大。
参考代码 2:使用栈模拟
public class Solution {
private enum Action {
/**
* 如果当前结点有孩子结点(左右孩子结点至少存在一个),执行 GO
*/
GO,
/**
* 添加到结果集(真正输出这个结点)
*/
ADDTORESULT
}
private class Command {
private Action action;
private TreeNode node;
/**
* 将动作类与结点类封装起来
*
* @param action
* @param node
*/
public Command(Action action, TreeNode node) {
this.action = action;
this.node = node;
}
}
public List<Integer> preorderTraversal(TreeNode root) {
List<Integer> res = new ArrayList<>();
if (root == null) {
return res;
}
Deque<Command> stack = new ArrayDeque<>();
stack.addLast(new Command(Action.GO, root));
while (!stack.isEmpty()) {
Command command = stack.removeLast();
if (command.action == Action.ADDTORESULT) {
res.add(command.node.val);
} else {
// 特别注意:以下的顺序与递归执行的顺序反着来,即:倒过来写的结果
// 前序遍历:根结点、左子树、右子树、
// 添加到栈的顺序:右子树、左子树、根结点
if (command.node.right != null) {
stack.add(new Command(Action.GO, command.node.right));
}
if (command.node.left != null) {
stack.add(new Command(Action.GO, command.node.left));
}
stack.add(new Command(Action.ADDTORESULT, command.node));
}
}
return res;
}
}复杂度分析:(同参考代码 1)。
说明:在理解了例 1 以后,例 2 和 例 3 可以类似地完成,我们不再对例 2 和例 3 进行详解、对复杂度展开分析,只给出参考代码。

在一些树的问题中,其实就是通过一次深度优先遍历,获得树的某些属性。例如:「二叉树」的最大深度、「二叉树」的最小深度、平衡二叉树、是否 BST。在遍历的过程中,通常需要设计一些变量,一边遍历,一边更新设计的变量的值。
「力扣」第 129 题:求根到叶子节点数字之和(中等)
public int sumNumbers(TreeNode root) {
return dfs(root,0);
}
public int dfs(TreeNode root,int prevSum){
if(root == null){
return 0;
}
int sum = prevSum * 10 + root.val;
if(root.left == null && root.right == null){
return sum;
}else{
return dfs(root.left,sum) + dfs(root.right,sum);
}
}友情提示:既然可以一层一层得到一个数,广度优先遍历也是很自然的想法,读者可以尝试使用广度优先遍历的思想完成该问题。
「力扣」第 323 题:无向图中连通分量的数目(中等)
思路分析:
首先需要对输入数组进行处理,由于 n 个结点的编号从 0 到 n - 1 ,因此使用「嵌套数组」表示邻接表即可(具体实现见代码); 然后遍历每一个顶点,对每一个顶点执行一次深度优先遍历,注意:在遍历的过程中使用 visited 布尔数组记录已经遍历过的结点。
public class Solution {
public int countComponents(int n, int[][] edges) {
// 第 1 步:构建图
List<Integer>[] adj = new ArrayList[n];
for (int i = 0; i < n; i++) {
adj[i] = new ArrayList<>();
}
// 无向图,所以需要添加双向引用
for (int[] edge : edges) {
adj[edge[0]].add(edge[1]);
adj[edge[1]].add(edge[0]);
}
// 第 2 步:开始深度优先遍历
int count = 0;
boolean[] visited = new boolean[n];
for (int i = 0; i < n; i++) {
if (!visited[i]) {
dfs(adj, i, visited);
count++;
}
}
return count;
}
/**
* @param adj 邻接表
* @param u 从顶点 u 开始执行深度优先遍历
* @param visited 记录某个结点是否被访问过
*/
private void dfs(List<Integer>[] adj, int u, boolean[] visited) {
visited[u] = true;
List<Integer> successors = adj[u];
for (int successor : successors) {
if (!visited[successor]) {
dfs(adj, successor, visited);
}
}
}
}我们分别通过两个例子讲解「无向图」中环的检测和「有向图」中环的检测(是不是要讲一下拓扑排序)。
例 3:「力扣」第 684 题:冗余连接(中等)
import java.util.ArrayList;
import java.util.HashMap;
import java.util.HashSet;
import java.util.List;
import java.util.Map;
import java.util.Set;
public class Solution {
private Map<Integer, List<Integer>> graph;
private Set<Integer> visited;
public int[] findRedundantConnection(int[][] edges) {
this.graph = new HashMap<>();
this.visited = new HashSet<>();
// 遍历每一条边
for (int[] edge : edges) {
int u = edge[0];
int v = edge[1];
if (graph.containsKey(u) && graph.containsKey(v)) {
visited.clear();
// 深度优先遍历该图,判断 u 到 v 之间是否已经存在了一条路径
if (dfs(u, v)) {
return edge;
}
}
// 所有相邻顶点都找不到回路,才向图中添加这条边,由于是无向图,所以要添加两条边
addEdge(u, v);
addEdge(v, u);
}
return null;
}
private void addEdge(int u, int v) {
if (graph.containsKey(u)) {
graph.get(u).add(v);
return;
}
List<Integer> successors = new ArrayList<>();
successors.add(v);
graph.put(u, successors);
}
/**
* 从 source 开始进行深度优先遍历,看看是不是能够找到一条到 target 的回路
*
* @param source
* @param target
* @return 找不到回路返回 false
*/
private boolean dfs(int source, int target) {
if (source == target) {
return true;
}
visited.add(source);
// 遍历 source 的所有相邻顶点
for (int adj : graph.get(source)) {
if (!visited.contains(adj)) {
if (dfs(adj, target)) {
return true;
}
}
}
// 所有相邻顶点都找不到,才能返回 false
return false;
}
}友情提示:该问题还可以使用拓扑排序完成。事实上,无向图找是否存在环是「并查集」这个数据结构的典型应用。
「力扣」第 802 题:找到最终的安全状态(中等)
import java.util.ArrayList;
import java.util.List;
public class Solution {
/**
* 使用 Boolean 利用了 null 表示还未计算出结果
* true 表示从当前顶点出发的所有路径有回路
* false 表示从当前顶点出发的所有路径没有回路
*/
private Boolean[] visited;
public List<Integer> eventualSafeNodes(int[][] graph) {
int len = graph.length;
visited = new Boolean[len];
List<Integer> res = new ArrayList<>();
for (int i = 0; i < len; ++i) {
if (dfs(i, graph)) {
continue;
}
res.add(i);
}
return res;
}
/**
* @param u
* @param graph
* @return 从顶点 u 出发的所有路径是不是有一条能够回到 u,有回路就返回 true
*/
private boolean dfs(int u, int[][] graph) {
if (visited[u] != null) {
return visited[u];
}
// 先默认从 u 出发的所有路径有回路
visited[u] = true;
// 结点 u 的所有后继结点都不能回到自己,才能认为结点 u 是安全的
for (int successor : graph[u]) {
if (dfs(successor, graph)) {
return true;
}
}
// 注意:这里需要重置
visited[u] = false;
return false;
}
}复杂度分析:
-
时间复杂度:O(V + E)O(V+E),这里 VV 为图的顶点总数,EE 为图的边数;
-
空间复杂度:O(V + E)O(V+E)。
总结:
- 在声明变量、设计递归函数的时候,一定要明确递归函数的变量的定义和递归函数的返回值,写上必要的注释,这样在编写代码逻辑的时候,才不会乱。
友情提示:还可以使用拓扑排序(借助入度和广度优先遍历)或者并查集两种方法完成。
「力扣」第 210 题:课程表 II(中等)
现在你总共有 n 门课需要选,记为 0 到 n-1。
在选修某些课程之前需要一些先修课程。 例如,想要学习课程 0 ,你需要先完成课程 1 ,我们用一个匹配来表示他们: [0,1]。
给定课程总量以及它们的先决条件,返回你为了学完所有课程所安排的学习顺序。
可能会有多个正确的顺序,你只要返回一种就可以了。如果不可能完成所有课程,返回一个空数组。
示例 1:
输入: 2, [[1,0]] 输出: [0,1] 解释: 总共有 2 门课程。要学习课程 1,你需要先完成课程 0。因此,正确的课程顺序为 [0,1] 。示例 2:
输入: 4, [[1,0],[2,0],[3,1],[3,2]] 输出: [0,1,2,3] or [0,2,1,3] 解释: 总共有 4 门课程。要学习课程 3,你应该先完成课程 1 和课程 2。并且课程 1 和课程 2 都应该排在课程 0 之后。因此,一个正确的课程顺序是 [0,1,2,3] 。另一个正确的排序是 [0,2,1,3] 。
说明:
-
输入的先决条件是由边缘列表表示的图形,而不是邻接矩阵。
-
你可以假定输入的先决条件中没有重复的边。
提示:
- 这个问题相当于查找一个循环是否存在于有向图中。如果存在循环,则不存在拓扑排序,因此不可能选取所有课程进行学习。
思路分析:
- 题目中提示已经说得很清楚了,要求我们在「有向图」中检测是否有环,如果没有环,则输出拓扑排序的结果;
- 所谓「拓扑排序」需要保证:① 每一门课程只出现一次;② 必需保证先修课程的顺序在所有它的后续课程的前面;
- 拓扑排序的结果不唯一,并且只有「有向无环图」才有拓扑排序;
- 关键要把握题目的要求:「必需保证先修课程的顺序在所有它的后续课程的前面」,「所有」关键字提示我们可以使用「 遍历」的思想遍历当前课程的 所有 后续课程,并且保证这些课程之间的学习顺序不存在「环」,可以使用「深度优先遍历」或者「广度优先遍历」;
- 我们这里给出「深度优先遍历」的实现代码,注意:需要在当前课程的所有 后续课程 结束以后才输出当前课程,所以 ① 收集结果的位置应该在「后序」的位置(类比二叉树的后序遍历);② 后序遍历的结果需要逆序才是拓扑排序的结果;
- 事实上,「拓扑排序」问题使用「广度优先遍历」的思想和实现是更经典的做法,我们放在「广度优先遍历」专题里向大家介绍。
编码前的说明:
深度优先遍历的写法需要注意:
- 递归函数返回值的意义:这里返回 true 表示在有向图中找到了环,返回 false 表示没有环;
- 我们扩展了布尔数组 visited 的含义,如果在无向图中,只需要 true 和 false 两种状态。在有向图中,为了检测是否存在环,我们新增一个状态,用于表示在对一门课程进行深度优先遍历的过程中,已经被标记,使用整数 1 表示。原来的 false 用整数 0 表示,含义为还未访问;原来的 true 用整数 2 表示,含义为「已经访问」,确切地说是「当前课程的所有后续课程」已经被访问。
public class Solution {
public int[] findOrder(int numCourses, int[][] prerequisites) {
// 步骤 1:构建邻接表
Set<Integer>[] adj = new HashSet[numCourses];
for (int i = 0; i < numCourses; i++) {
adj[i] = new HashSet<>();
}
int pLen = prerequisites.length;
for (int i = 0; i < pLen; i++) {
// 后继课程
int second = prerequisites[i][0];
// 先行课程
int first = prerequisites[i][1];
// 注意 dfs 中,后继课程作为 key,前驱课程作为 value,这种方式不符合邻接表的习惯,邻接表总是通过前驱得到后继
adj[second].add(first);
}
// 步骤二:对每一个结点执行一次深度优先遍历
// 0 表示没有访问过,对应于 boolean 数组里的 false
// 1 表示已经访问过,新增状态,如果 dfs 的时候遇到 1 ,表示当前遍历的过程中形成了环
// 2 表示当前结点的所有后继结点已经遍历完成,对应于 boolean 数组里的 true
int[] visited = new int[numCourses];
List<Integer> res = new ArrayList<>();
for (int i = 0; i < numCourses; i++) {
// 对每一个结点执行一次深度优先遍历
if (dfs(i, adj, visited, res)) {
return new int[]{};
}
}
return res.stream().mapToInt(i -> i).toArray();
}
/**
* @param current
* @param adj
* @param visited
* @param res
* @return true 表示有环,false 表示没有环
*/
private boolean dfs(int current, Set<Integer>[] adj,
int[] visited, List<Integer> res) {
if (visited[current] == 1) {
return true;
}
if (visited[current] == 2) {
return false;
}
visited[current] = 1;
for (Integer successor : adj[current]) {
if (dfs(successor, adj, visited, res)) {
// 如果有环,返回空数组
return true;
}
}
// 注意:在「后序」这个位置添加到结果集
res.add(current);
visited[current] = 2;
// 所有的后继结点都遍历完成以后,都没有遇到重复,才可以说没有环
return false;
}
}复杂度分析:
- 时间复杂度:O(V + E),这里 V 表示课程总数,E 表示课程依赖关系总数,对每一个顶点执行一次深度优先遍历,所有顶点需要遍历的操作总数与边总数有关;
- 空间复杂度:O(V + E),邻接表的大小为 V + E,递归调用栈的深度最多为 V,因此空间复杂度是 O(V + E)。
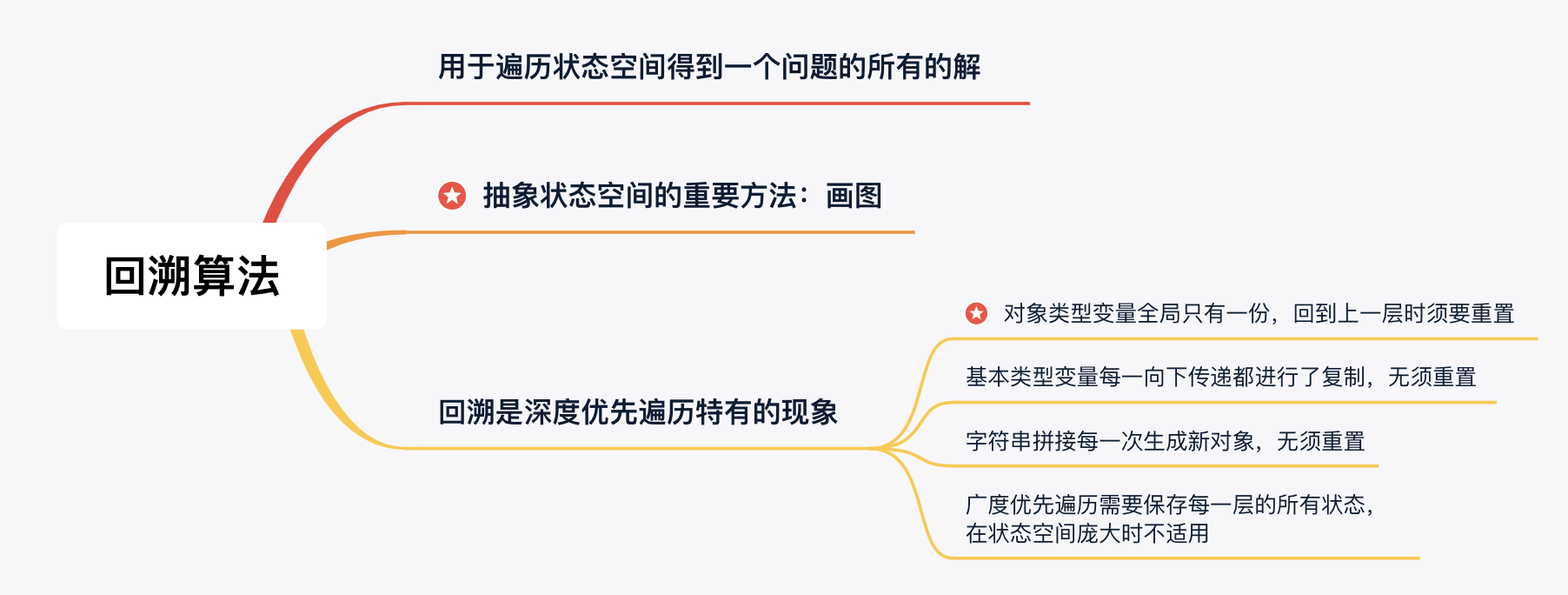
回溯算法是一种通过不断 尝试 ,搜索一个问题的一个解或者 所有解 的方法。在求解的过程中,如果继续求解不能得到题目要求的结果,就需要 回退 到上一步尝试新的求解路径。回溯算法的核心思想是:在一棵 隐式的树(看不见的树) 上进行一次深度优先遍历。
我们通过一道经典的问题 N 皇后问题,向大家介绍「回溯算法」的思想。
n 皇后问题研究的是如何将 n 个皇后放置在 n×n 的棋盘上,并且使皇后彼此之间不能相互攻击。
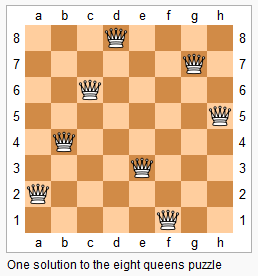
上图为 8 皇后问题的一种解法。
给定一个整数 n,返回所有不同的 n 皇后问题的解决方案。
每一种解法包含一个明确的 n 皇后问题的棋子放置方案,该方案中 'Q' 和 '.' 分别代表了皇后和空位。
输入:4
输出:[
[".Q..", // 解法 1
"...Q",
"Q...",
"..Q."],
["..Q.", // 解法 2
"Q...",
"...Q",
".Q.."]
]
解释: 4 皇后问题存在两个不同的解法。
提示:
- 皇后彼此不能相互攻击,也就是说:任何两个皇后都不能处于同一条横行、纵行或斜线上。
思路分析:解决这个问题的思路是尝试每一种可能,然后逐个判断。只不过回溯算法按照一定的顺序进行尝试,在一定不可能得到解的时候进行剪枝,进而减少了尝试的可能。下面的幻灯片展示了整个搜索的过程。
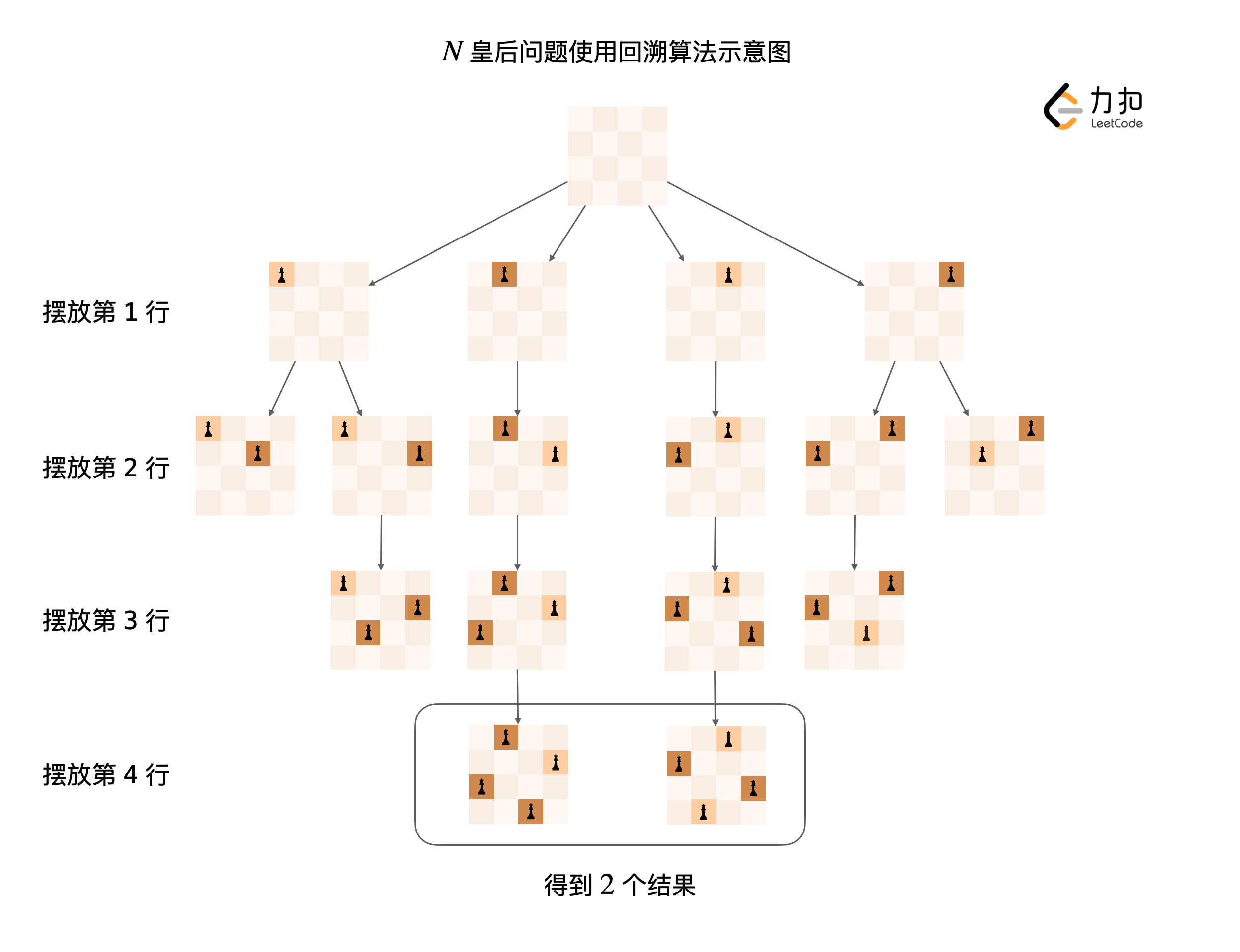
在遍历的过程中记录已经放置的皇后的位置
由于我们需要根据前面已经放置的皇后的位置,来决定当前位置是否可以放置皇后,因此记住已经放置的皇后的位置就很重要。
- 由于我们一行一行考虑放置皇后,摆放的这些皇后肯定不在同一行;
- 为了避免它们在同一列,需要一个长度为 NN 的布尔数组 cols,已经放置的皇后占据的列,就需要在对应的列的位置标记为 true;
- 还需要考虑「任何两个皇后不能位于同一条斜线上」,下面的图展示了位于一条斜线上的皇后的位置特点。
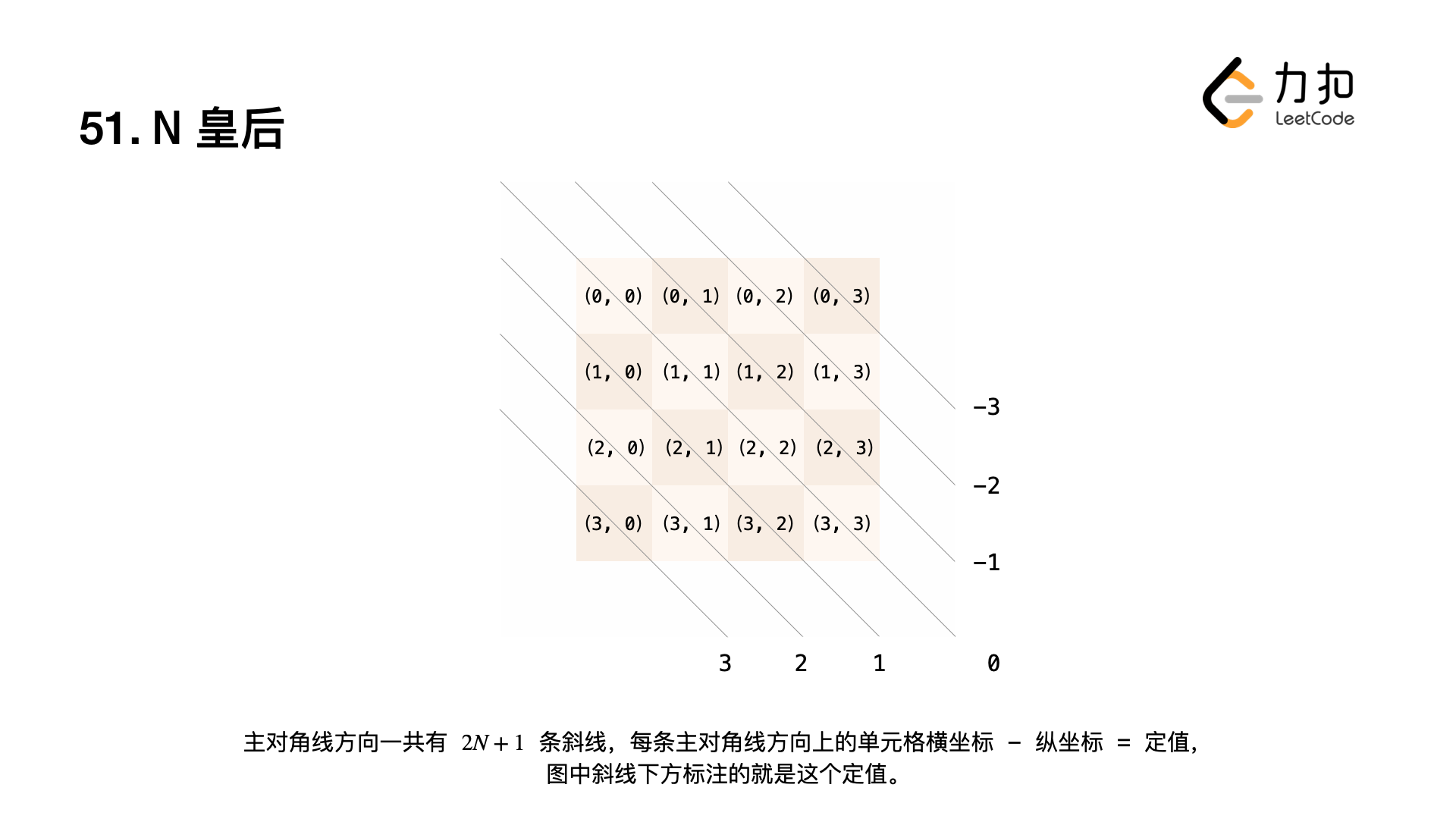
为此,我们需要一个表示主对角线方向的布尔数组 main(Main diagonal,长度为 2N-12N−1),如果某个单元格放放置了一个皇后,就需要将对应的主对角线标记为 true。注意:由于有 3 个方向的横坐标 - 纵坐标的结果为负值,可以统一地为每一个横坐标 - 纵坐标的结果增加一个偏移,具体请见参考代码 1。

同理,我们还需要一个表示副对角线方向的布尔数组 sub(Sub diagonal,长度为 2N-12N−1),如果某个单元格放放置了一个皇后,就需要将对应的副对角线标记为 true。
import java.util.ArrayDeque;
import java.util.ArrayList;
import java.util.Deque;
import java.util.List;
public class Solution {
private int n;
/**
* 记录某一列是否放置了皇后
*/
private boolean[] col;
/**
* 记录主对角线上的单元格是否放置了皇后
*/
private boolean[] main;
/**
* 记录了副对角线上的单元格是否放置了皇后
*/
private boolean[] sub;
private List<List<String>> res;
public List<List<String>> solveNQueens(int n) {
res = new ArrayList<>();
if (n == 0) {
return res;
}
// 设置成员变量,减少参数传递,具体作为方法参数还是作为成员变量,请参考团队开发规范
this.n = n;
this.col = new boolean[n];
this.main = new boolean[2 * n - 1];
this.sub = new boolean[2 * n - 1];
Deque<Integer> path = new ArrayDeque<>();
dfs(0, path);
return res;
}
private void dfs(int row, Deque<Integer> path) {
if (row == n) {
// 深度优先遍历到下标为 n,表示 [0.. n - 1] 已经填完,得到了一个结果
List<String> board = convert2board(path);
res.add(board);
return;
}
// 针对下标为 row 的每一列,尝试是否可以放置
for (int j = 0; j < n; j++) {
if (!col[j] && !main[row - j + n - 1] && !sub[row + j]) {
path.addLast(j);
col[j] = true;
main[row - j + n - 1] = true;
sub[row + j] = true;
dfs(row + 1, path);
sub[row + j] = false;
main[row - j + n - 1] = false;
col[j] = false;
path.removeLast();
}
}
}
private List<String> convert2board(Deque<Integer> path) {
List<String> board = new ArrayList<>();
for (Integer num : path) {
StringBuilder row = new StringBuilder();
row.append(".".repeat(Math.max(0, n)));
row.replace(num, num + 1, "Q");
board.add(row.toString());
}
return board;
}
}复杂度分析:
-
时间复杂度:O(N!)O(N!),这里 NN 为皇后的个数,这里讨论的时间复杂度很宽松,第一行皇后可以摆放的位置有 NN 个,第二行皇后可以摆放的位置有 N - 1N−1 个,依次类推下去,按照分步计数乘法原理,一共有 N!N! 种可能;
-
空间复杂度:O(N)O(N),递归调用栈的深度最多为 NN,三个布尔数组的长度分别为 NN、2N+12N+1、2N+12N+1,都是 NN 的线性组合。
其实,判断是否重复,可以使用哈希表,下面给出的参考代码 2 就使用了哈希表判断是否重复,可以不用处理主对角线方向上「横坐标 - 纵坐标」的下标偏移。但事实上,哈希表底层也是数组。
回溯算法其实是在一棵隐式的树或者图上进行了一次深度优先遍历,我们在解决问题的过程中需要把问题抽象成一个树形问题。充分理解树形问题最好的办法就是用一个小的测试用例,在纸上画出树形结构图,然后再针对树形结构图进行编码。
重要的事情我们说三遍:画图分析很重要、画图分析很重要、画图分析很重要。
要理解「回溯算法」的递归前后,变量需要恢复也需要想象代码是在一个树形结构中执行深度优先遍历,回到以前遍历过的结点,变量需要恢复成和第一次来到该结点的时候一样的值。
另一个理解回溯算法执行流程的重要方法是:在递归方法执行的过程中,将涉及到的变量的值打印出来看,观察变量的值的变化。
友情提示:画图分析问题是思考算法问题的重要方法,画图这个技巧在解决链表问题、回溯算法、动态规划的问题上都有重要的体现,请大家不要忽视「画图」这个简单的分析问题的方法,很多时候思路就出现在我们在草稿纸上写写画画以后。
问「一个问题 所有的 解」一般考虑使用回溯算法。因此回溯算法也叫「暴力搜索」,但不同于最粗暴的多个 for 循环,回溯算法是有方向的遍历。
计算机擅长做的事情是「计算」,即「做重复的事情」。能用编程的方法解决的问题通常 结构相同,问题规模不同。因此,我们解决一个问题的时候,通常需要将问题一步一步进行拆解,把一个大问题拆解为结构相同的若干个小问题。
友情提示:我们介绍「状态」和「状态空间」这两个概念是为了方便后面的问题描述,其实大家在完成了一定练习以后对这两个概念就会有形象的理解。如果一开始不理解这些概念完全可以跳过。
为了区分解决问题的不同阶段、不同规模,我们可以通过语言描述进行交流。在算法的世界里,是通过变量进行描述的,不同的变量的值就代表了解决一个实际问题中所处的不同的阶段,这些变量就叫做「状态变量」。所有的状态变量构成的集合称为「状态空间」。
友情提示:「空间」这个词经常代表的含义是「所有」。在《线性代数》里,线性空间(向量空间)就是规定了「加法」和「数乘」,且对这两种运算封闭的 所有 元素的集合。
我们可以把某种规模的问题描述想象成一个结点。由于规模相近的问题之间存在联系,我们把有联系的结点之间使用一条边连接,因此形成的状态空间就是一张图。
树结构有唯一的起始结点(根结点),且不存在环,树是特殊的图。这一章节绝大多数的问题都从一个基本的问题出发,拆分成多个子问题,并且继续拆分的子问题没有相同的部分,因此这一章节遇到的绝大多数问题的状态空间是一棵树。
我们要了解这个问题的状态空间,就需要通过 遍历 的方式。正是因为通过遍历,我们能够访问到状态空间的所有结点,因此可以获得一个问题的 所有 解。
而「回溯」就是 深度优先遍历 状态空间的过程中发现的特有的现象,程序会回到以前访问过的结点。而程序在回到以前访问过的结点的时候,就需要将状态变量恢复成为第一次来到该结点的值。
在代码层面上,在递归方法结束以后,执行递归方法之前的操作的 逆向操作 即可。
友情提示:理解回溯算法的「回溯」需要基于一定的练习,可以不必一开始就理解透彻。另外,理解「回溯算法」的一个重要技巧是 在程序中打印状态变量进行观察,一步一步看到变量的变化。
- 当回到上一级的时候,所有的状态变量需要重置为第一次来到该结点的状态,这样继续尝试新的选择才有意义;
- 在代码层面上,需要在递归结束以后,添加递归之前的操作的逆向操作;
基本类型变量每一次向下传递的时候的行为是复制,所以无需重置; 对象类型变量在遍历的全程只有一份,因此再回退的时候需要重置; 类比于 Java 中的 方法参数 的传递机制: 基本类型变量在方法传递的过程中的行为是复制,每一次传递复制了参数的值; 对象类型变量在方法传递的过程中复制的是对象地址,对象全程在内存中共享地址。
如果使用 + 拼接字符串,每一次拼接产生新的字符串,因此无需重置; 如果使用 StringBuilder 拼接字符串,整个搜索的过程 StringBuilder 对象只有一份,需要状态重置。
广度优先遍历每一层需要保存所有的「状态」,如果状态空间很大,需要占用很大的内存空间; 深度优先遍历只要有路径可以走,就继续尝试走新的路径,不同状态的差距只有一个操作,而广度优先遍历在不同的层之前,状态差异很大,就不能像深度优先遍历一样,可以 使用一份状态变量去遍历所有的状态空间,在合适的时候记录状态的值就能得到一个问题的所有的解。
- 完成「力扣」第 46 题:全排列(中等);
- 完成「力扣」第 37 题:数独(困难);
下面是字符串的搜索问题,完成这些问题可以帮助理解回溯算法的实现细节。
- 完成「力扣」第 22 题:括号生成(中等);
- 完成「力扣」第 17 题:电话号码的字母组合(中等);
- 完成「力扣」第 784 题:字母大小写全排列(中等)。
剪枝的想法是很自然的。回溯算法本质上是遍历算法,如果 在遍历的过程中,可以分析得到这样一条分支一定不存在需要的结果,就可以跳过这个分支。
发现剪枝条件依然是通过举例的例子,画图分析,即:通过具体例子抽象出一般的剪枝规则。通常可以选取一些较典型的例子,以便抽象出一般规律。
友情提示:阅读下面的文字,可能会有一些晦涩,建议大家了解思路,通过对具体例子的分析,逐渐分析出解决这个问题的细节。
按照顺序搜索其实也是去除重复结果的必要条件。
「力扣」第 47 题:全排列 II
给定一个可包含重复数字的序列 nums ,按任意顺序 返回所有不重复的全排列。
示例 1:
输入:nums = [1,1,2] 输出: [[1,1,2], [1,2,1], [2,1,1]]示例 2:
输入:nums = [1,2,3] 输出:[[1,2,3],[1,3,2],[2,1,3],[2,3,1],[3,1,2],[3,2,1]]
思路分析:
- 这道题基于「力扣」第 46 题(全排列)的思想完成,首先依然是先画出树形结构,然后编写深度优先遍历的代码,在遍历的过程中收集所有的全排列;
- 与「力扣」第 46 题(全排列)不同的是:输入数组中有重复元素,如果还按照第 46 题的写法做,就会出现重复列表;
- 如果搜索出来结果列表,再在结果列表里去重,比较相同的列表是一件比较麻烦的事情,我们可以 ①:依次对列表排序,再逐个比较列表中的元素;② 将列表封装成为类,使用哈希表去重的方式去掉重复的列表。这两种方式编码都不容易实现;
- 既然需要排序,我们可以在一开始的时候,就对输入数组进行排序,在遍历的过程中,通过一定剪枝条件,发现一定会搜索到重复元素的结点,跳过它,这样在遍历完成以后,就能得到不重复的列表。
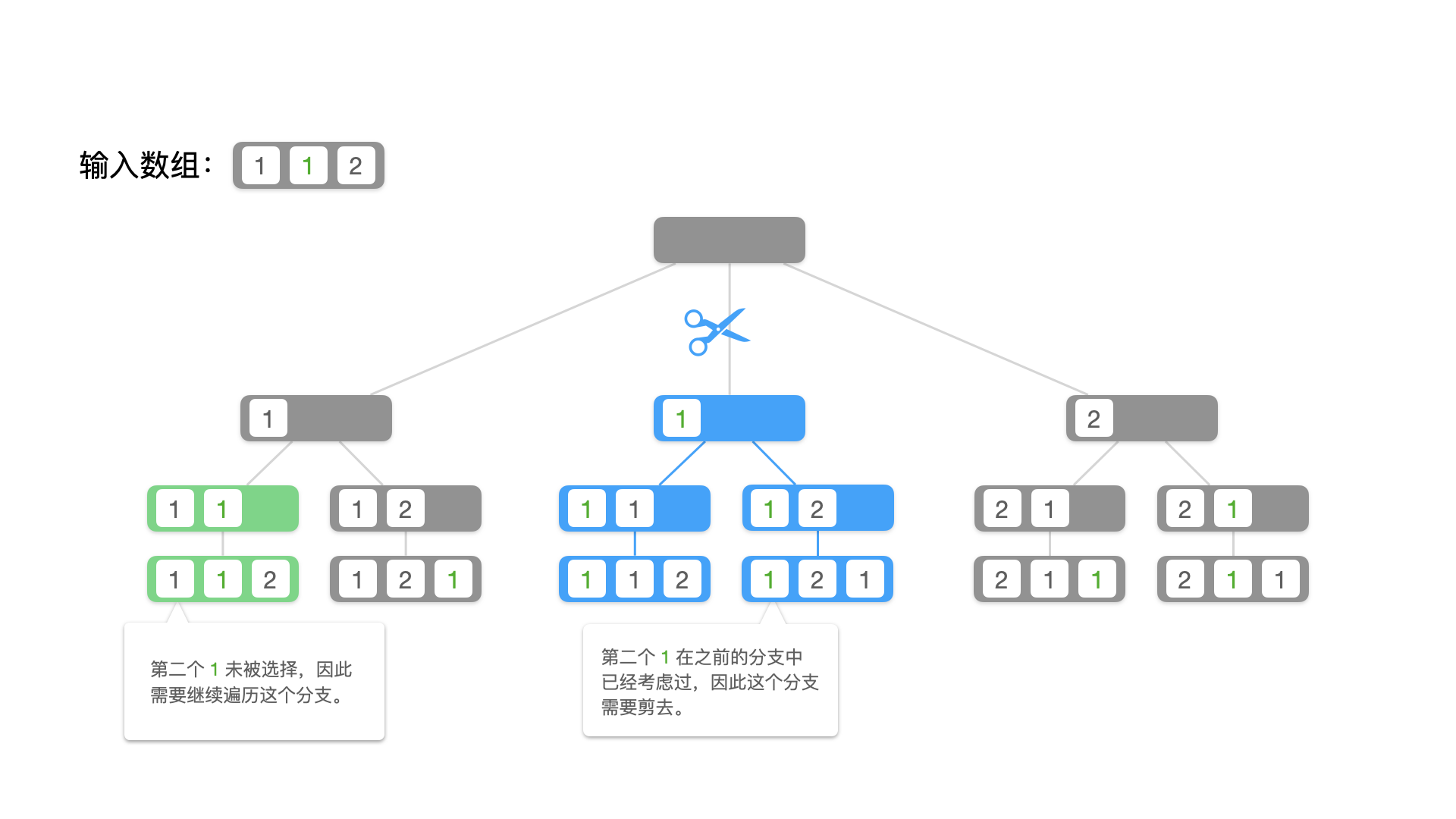
我们画出树形图,找出它们重复的部分,进而发现产生重复的原因。
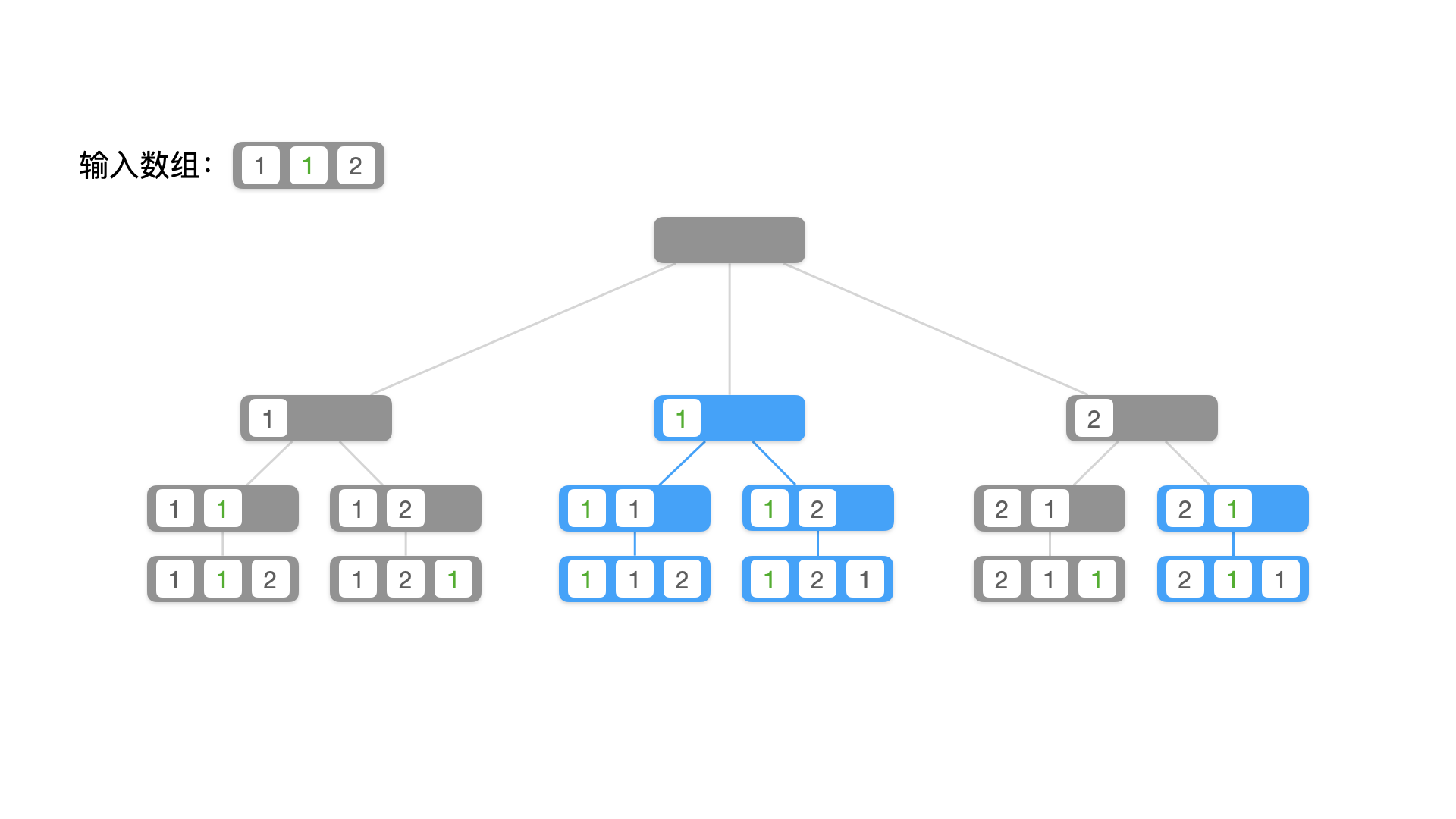
产生重复列表的原因:
- 很容易看到,在树的同一层,如果当前考虑的数字相同,就有可能搜索到重复的结果(前提:输入数组按照升序排序),因此剪枝条件为 nums[i] == nums[i - 1] 这里为了保证数组下标不越界,前提是 i > 0;
- 光有这个条件还不够,我们观察下面两个分支,中间被着重标注的分支,满足 nums[i] == nums[i - 1] 并且 nums[i - 1] 还未被使用,就下来由于还要使用 1 一定会与前一个分支搜索出的结果重复;
- 而左边被着重标注的分支,也满足 nums[i] == nums[i - 1] ,但是 nums[i - 1] 已经被使用,接下来不会再用到它,因此不会产生重复。
import java.util.ArrayDeque;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Deque;
import java.util.List;
public class Solution {
public List<List<Integer>> permuteUnique(int[] nums) {
int len = nums.length;
List<List<Integer>> res = new ArrayList<>();
if (len == 0) {
return res;
}
// 剪枝的前提是排序
Arrays.sort(nums);
boolean[] used = new boolean[len];
// 使用 Deque 是 Java 官方 Stack 类的建议
Deque<Integer> path = new ArrayDeque<>(len);
dfs(nums, 0, len, used, path, res);
return res;
}
private void dfs(int[] nums, int index, int len, boolean[] used, Deque<Integer> path, List<List<Integer>> res) {
if (index == len) {
res.add(new ArrayList<>(path));
return;
}
for (int i = 0; i < len; i++) {
if (used[i]) {
continue;
}
// 注意:理解 !used[i - 1],很关键
// 剪枝条件:i > 0 是为了保证 nums[i - 1] 有意义
// 写 !used[i - 1] 是因为 nums[i - 1] 在深度优先遍历的过程中刚刚被撤销选择
if (i > 0 && nums[i] == nums[i - 1] && !used[i - 1]) {
continue;
}
used[i] = true;
path.addLast(nums[i]);
dfs(nums, index + 1, len, used, path, res);
// 回溯部分的代码,和 dfs 之前的代码是对称的
used[i] = false;
path.removeLast();
}
}
}「力扣」第 39 题:(组合问题)
给定一个无重复元素的数组 candidates 和一个目标数 target ,找出 candidates 中所有可以使数字和为 target 的组合。
candidates 中的数字可以无限制重复被选取。
说明:
- 所有数字(包括 target)都是正整数。
- 解集不能包含重复的组合。
示例 1:
输入:candidates = [2,3,6,7], target = 7, 所求解集为: [ [7], [2,2,3] ]
思路分析:有了之前问题的求解经验,我们 强烈建议 大家使用示例 1 ,以自己熟悉的方式画出树形结构,再尝试编码、通过调试的方式把这个问题做出来。
- 可以从目标值 target = 7 开始,逐个减去 2 、3 、6 、7 ,把问题转化成使用 [2, 3, 6, 7] 能够得到的组合之和为 5、 4、 1、0 的所有列表,如果能够得到有效的列表,再加上减去的那个数,就是原始问题的一个列表,这是这个问题的递归结构;
- 减去一个数以后,得到的数为 0 或者负数以后,就可以停止了,请大家想一想这是为什么。画好这棵树以后,我们关注叶子结点的值为 0 的结点,从根结点到叶子结点的一条路径,满足沿途减去的数的和为 target = 7;

- 由于这个问题得到的结果是组合,[2, 2, 3]、[2, 3, 2] 与 [3, 2, 2] 只能作为一个列表在结果集里输出,我们依然是按照第 47 题的分析,在图中标注出这些重复的分支,发现剪枝的条件;
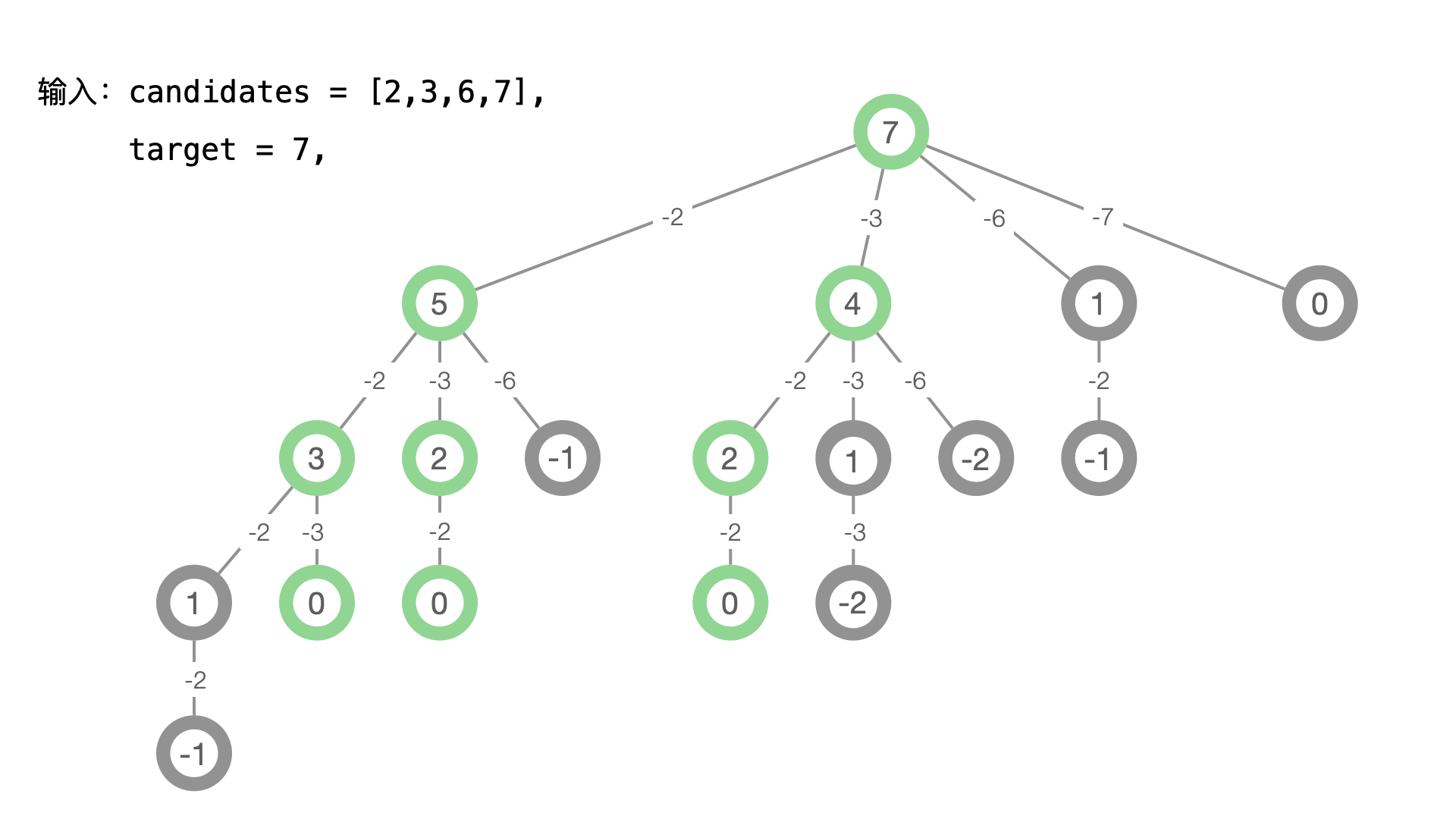
- 去除重复的方法通常是按照一定的顺序考虑问题,我们观察重复的三个列表 [2, 2, 3]、[2, 3, 2] 与 [2, 3, 2] ,我们只需要一个,保留自然顺序 [2, 2, 3] 即可,于是我们可以指定如下规则:如果在深度较浅的层减去的数等于 a ,那么更深的层只能减去大于等于 a 的数(根据题意,一个元素可以使用多次,因此可以减去等于 a 的数),这样就可以跳过重复的分支,深度优先遍历得到的结果就不会重复;
- 容易发现,如果减去一个数的值小于 0 ,就没有必要再减去更大的数,这也是可以剪枝的地方。
public class Solution {
public List<List<Integer>> combinationSum(int[] candidates, int target) {
int len = candidates.length;
List<List<Integer>> res = new ArrayList<>();
if (len == 0) {
return res;
}
// 排序是剪枝的前提
Arrays.sort(candidates);
Deque<Integer> path = new ArrayDeque<>();
dfs(candidates, 0, len, target, path, res);
return res;
}
private void dfs(int[] candidates, int begin, int len, int target, Deque<Integer> path, List<List<Integer>> res) {
// 由于进入更深层的时候,小于 0 的部分被剪枝,因此递归终止条件值只判断等于 0 的情况
if (target == 0) {
res.add(new ArrayList<>(path));
return;
}
for (int i = begin; i < len; i++) {
// 重点理解这里剪枝,前提是候选数组已经有序
if (target - candidates[i] < 0) {
break;
}
path.addLast(candidates[i]);
dfs(candidates, i, len, target - candidates[i], path, res);
path.removeLast();
}
}
}如果对这个问题研究比较深入,可以发现,其实只要保持深层结点不重复使用浅层结点使用过的数值即可,也就是说排序对于这道问题来说不是必须的,排序用于提速,而真正去除重复元素的技巧是:设置搜索起点,这是另一种意义上的按顺序搜索(搜索起点不回头)。下面的代码也可以通过系统测评。
import java.util.ArrayDeque;
import java.util.ArrayList;
import java.util.Deque;
import java.util.List;
public class Solution {
public List<List<Integer>> combinationSum(int[] candidates, int target) {
int len = candidates.length;
List<List<Integer>> res = new ArrayList<>();
if (len == 0) {
return res;
}
Deque<Integer> path = new ArrayDeque<>();
dfs(candidates, 0, len, target, path, res);
return res;
}
/**
* @param candidates 候选数组
* @param begin 搜索起点
* @param len 冗余变量,是 candidates 里的属性,可以不传
* @param target 每减去一个元素,目标值变小
* @param path 从根结点到叶子结点的路径,是一个栈
* @param res 结果集列表
*/
private void dfs(int[] candidates, int begin, int len, int target, Deque<Integer> path, List<List<Integer>> res) {
// target 为负数和 0 的时候不再产生新的孩子结点
if (target < 0) {
return;
}
if (target == 0) {
res.add(new ArrayList<>(path));
return;
}
// 重点理解这里从 begin 开始搜索的语意
for (int i = begin; i < len; i++) {
path.addLast(candidates[i]);
// 注意:由于每一个元素可以重复使用,下一轮搜索的起点依然是 i,这里非常容易弄错
dfs(candidates, i, len, target - candidates[i], path, res);
// 状态重置
path.removeLast();
}
}
}「力扣」第 77 题:子集(中等)
给定两个整数 n 和 k,返回 1 ... n 中所有可能的 k 个数的组合。
示例:
输入: n = 4, k = 2 输出: [ [2,4], [3,4], [2,3], [1,2], [1,3], [1,4], ]
思路分析:
- 依然是 强烈建议 大家在纸上根据示例画出树形结构图;
- 根据第 39 题的经验,可以设置搜索起点,以防止不重不漏;
- 如果对这个问题研究得比较深入,由于 k 是一个正整数,搜索起点不一定需要枚举到 n ,具体搜索起点的上限可以尝试举出一个数值合适的例子找找规律,我们在这里直接给出参考的代码。
参考代码:
import java.util.ArrayDeque;
import java.util.ArrayList;
import java.util.Deque;
import java.util.List;
public class Solution {
public List<List<Integer>> combine(int n, int k) {
List<List<Integer>> res = new ArrayList<>();
if (k <= 0 || n < k) {
return res;
}
Deque<Integer> path = new ArrayDeque<>(k);
dfs(n, k, 1, path, res);
return res;
}
// i 的极限值满足: n - i + 1 = (k - pre.size())
// n - i + 1 是闭区间 [i, n] 的长度
// k - pre.size() 是剩下还要寻找的数的个数
private void dfs(int n, int k, int index, Deque<Integer> path, List<List<Integer>> res) {
if (path.size() == k) {
res.add(new ArrayList<>(path));
return;
}
// 注意:这里搜索起点的上限为 n - (k - path.size()) + 1 ,这一步有很强的剪枝效果
for (int i = index; i <= n - (k - path.size()) + 1; i++) {
path.addLast(i);
dfs(n, k, i + 1, path, res);
path.removeLast();
}
}
}- 完成「力扣」第 40 题:组合总和 II(中等);
- 完成「力扣」第 78 题:子集(中等);
- 完成「力扣」第 90 题:子集 II(中等)。
- 完成「力扣」第 1593 题:拆分字符串使唯一子字符串的数目最大(中等);
- 完成「力扣」第 1079 题:活字印刷(中等)。
「剪枝」条件通常是具体问题具体分析,因此需要我们积累一定求解问题的经验。
「力扣」第 79 题:单词搜索(中等)
给定一个二维网格和一个单词,找出该单词是否存在于网格中。
单词必须按照字母顺序,通过相邻的单元格内的字母构成,其中“相邻”单元格是那些水平相邻或垂直相邻的单元格。同一个单元格内的字母不允许被重复使用。
board = [ ['A','B','C','E'], ['S','F','C','S'], ['A','D','E','E'] ] 给定 word = "ABCCED", 返回 true 给定 word = "SEE", 返回 true 给定 word = "ABCB", 返回 false
提示:
- board 和 word 中只包含大写和小写英文字母;
- 1 <= board.length <= 200
- 1 <= board[i].length <= 200
- 1 <= word.length <= 10^3
思路分析:
- 这道题要求我们在一个二维表格上找出给定目标单词 word 的一个路径,题目中说:「相邻」单元格是那些水平相邻或垂直相邻的单元格。也就是说:如果当前单元格恰好与 word 的某个位置的字符匹配,应该从当前单元格的上、下、左、右 44 个方向继续匹配剩下的部分;
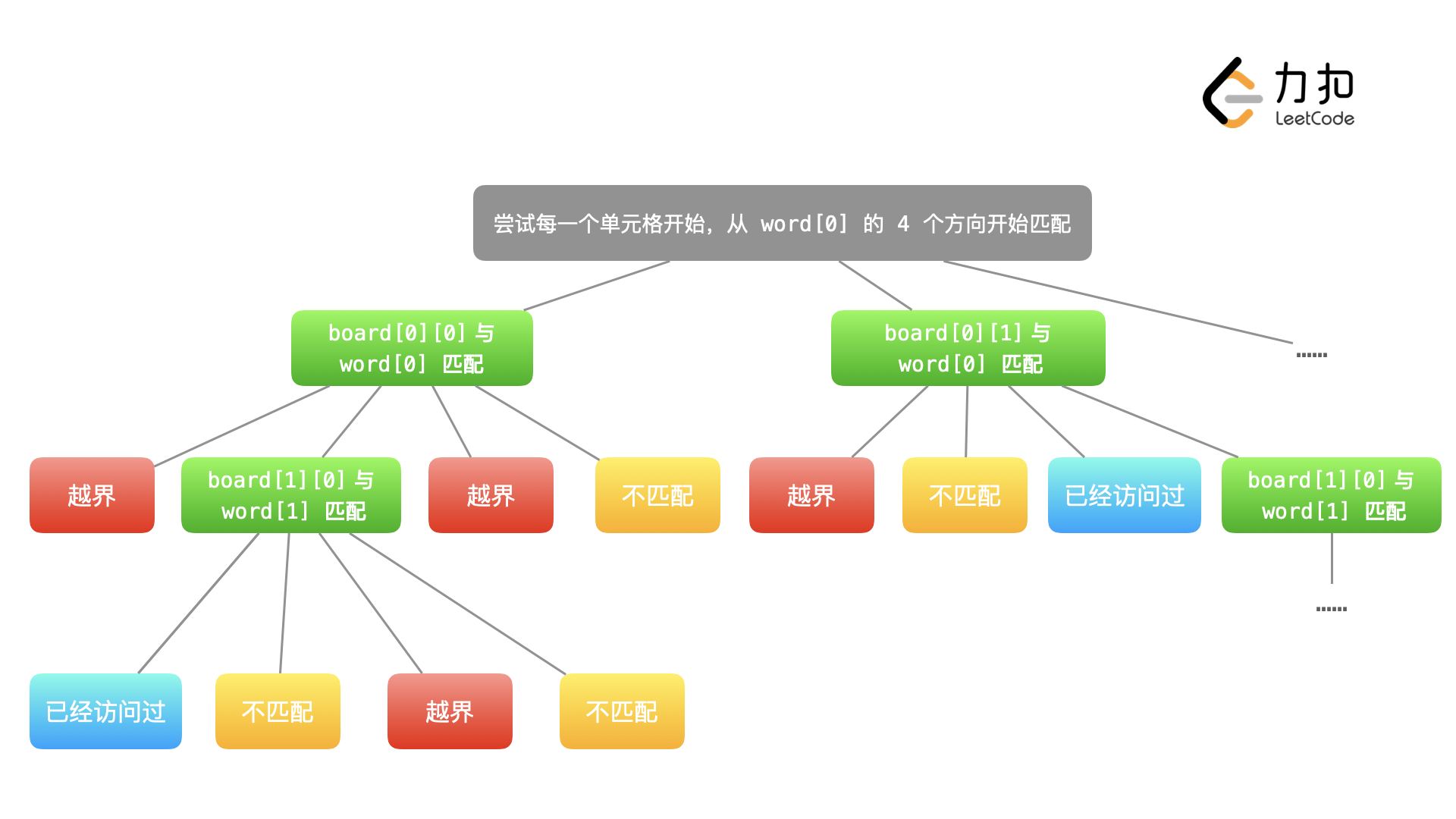
- 下面的幻灯片展示了整个匹配的过程,请大家注意:
- 对于每一个单元格,在第一个字符匹配的时候,才执行一次深度优先遍历,直到找到符合条件的一条路径结束。如果第一个字符都不匹配,当然没有必要继续遍历下去;
- 递归终止的条件是:匹配到了 word 的最后一个字符;
- 在不能匹配的时候,需要 原路返回,尝试新的路径。这一点非常重要,我们修改了题目中的示例,请大家仔细观察下面的幻灯片中的例子,体会「回溯」在什么时候发生?
整个搜索的过程可以用下面的树形结构表示,由于空间限制我们没有画出完整的树的样子,希望大家能够结合上面的幻灯片想清楚这个问题「当一条路径不能匹配的时候是如何回退的」,并且结合参考代码理解程序的执行流程。
public class Solution {
private boolean[][] visited;
private int[][] directions = {{-1, 0}, {0, -1}, {0, 1}, {1, 0}};
private int rows;
private int cols;
private int len;
private char[] charArray;
private char[][] board;
public boolean exist(char[][] board, String word) {
len = word.length();
rows = board.length;
if (rows == 0) {
return false;
}
cols = board[0].length;
visited = new boolean[rows][cols];
this.charArray = word.toCharArray();
this.board = board;
for (int i = 0; i < rows; i++) {
for (int j = 0; j < cols; j++) {
if (dfs(i, j, 0)) {
return true;
}
}
}
return false;
}
/**
* @param i
* @param j
* @param begin 从 word[begin] 处开始搜索
* @return
*/
private boolean dfs(int i, int j, int begin) {
// 字符串的最后一个字符匹配,即返回 true
if (begin == len - 1) {
return board[i][j] == charArray[begin];
}
// 只要当前考虑的字符能够匹配,就从四面八方继续搜索
if (board[i][j] == charArray[begin]) {
visited[i][j] = true;
for (int[] direction : directions) {
int newX = i + direction[0];
int newY = j + direction[1];
if (inArea(newX, newY) && !visited[newX][newY]) {
if (dfs(newX, newY, begin + 1)) {
return true;
}
}
}
visited[i][j] = false;
}
return false;
}
private boolean inArea(int x, int y) {
return x >= 0 && x < rows && y >= 0 && y < cols;
}
}说明:
- DIRECTIONS 表示方向数组,44 个元素分别表示下、右、上、左 44 个方向向量,顺序无关紧要,建议四连通、八连通的问题都这样写;
- 有一些朋友可能会觉得封装私有函数会降低程序的执行效率,这一点在一些编程语言中的确是这样,但是我们在日常编写代码的过程中,语义清晰和可读性是更重要的,因此在编写代码的时候,最好能够做到「一行代码只做一件事情」
「力扣」第 695 题:岛屿的最大面积(中等)
下面我们再展示一个问题,希望大家通过这个问题熟悉二维平面上回溯算法的编码技巧。
给定一个包含了一些 0 和 1 的非空二维数组 grid 。
一个 岛屿 是由一些相邻的 1 (代表土地) 构成的组合,这里的「相邻」要求两个 1 必须在水平或者竖直方向上相邻。你可以假设 grid 的四个边缘都被 0(代表水)包围着。
找到给定的二维数组中最大的岛屿面积。(如果没有岛屿,则返回面积为 0 。)
[[0,0,1,0,0,0,0,1,0,0,0,0,0], [0,0,0,0,0,0,0,1,1,1,0,0,0], [0,1,1,0,1,0,0,0,0,0,0,0,0], [0,1,0,0,1,1,0,0,1,0,1,0,0], [0,1,0,0,1,1,0,0,1,1,1,0,0], [0,0,0,0,0,0,0,0,0,0,1,0,0], [0,0,0,0,0,0,0,1,1,1,0,0,0], [0,0,0,0,0,0,0,1,1,0,0,0,0]]对于上面这个给定矩阵应返回
6。注意答案不应该是11,因为岛屿只能包含水平或垂直的四个方向的1。
思路分析:
找到一个岛屿,就是在 1(表示土地)的上、下、左、右 44 个方向执行一次深度优先遍历遍历,只要这 44 个方向上还有 1 ,就继续执行深度优先遍历。
递归实现
public class Solution {
private int[][] directions = {{-1, 0}, {0, 1}, {1, 0}, {0, -1}};
private int rows;
private int cols;
private int[][] grid;
private boolean[][] visited;
public int maxAreaOfIsland(int[][] grid) {
if (grid == null) {
return 0;
}
rows = grid.length;
if (rows == 0) {
return 0;
}
cols = grid[0].length;
if (cols == 0) {
return 0;
}
this.grid = grid;
this.visited = new boolean[rows][cols];
int res = 0;
for (int i = 0; i < rows; i++) {
for (int j = 0; j < cols; j++) {
if (grid[i][j] == 1 && !visited[i][j]) {
res = Math.max(res, dfs(i, j));
}
}
}
return res;
}
private int dfs(int x, int y) {
visited[x][y] = true;
int res = 1;
for (int[] direction:directions) {
int nextX = x + direction[0];
int nextY = y + direction[1];
if (inArea(nextX, nextY) && grid[nextX][nextY] == 1 && !visited[nextX][nextY]) {
res += dfs(nextX, nextY);
}
}
return res;
}
private boolean inArea(int x, int y) {
return x >= 0 && x < rows && y >= 0 && y < cols;
}
}模拟栈
import java.util.ArrayDeque;
import java.util.Deque;
public class Solution {
private final static int[][] DIRECTIONS = {{-1, 0}, {1, 0}, {0, -1}, {0, 1}};
public int maxAreaOfIsland(int[][] grid) {
int rows = grid.length;
int cols = grid[0].length;
boolean[][] visited = new boolean[rows][cols];
int maxArea = 0;
for (int i = 0; i < rows; i++) {
for (int j = 0; j < cols; j++) {
if (grid[i][j] == 1 && !visited[i][j]) {
maxArea = Math.max(maxArea, dfs(grid, i, j, rows, cols, visited));
}
}
}
return maxArea;
}
private int dfs(int[][] grid, int i, int j, int rows, int cols, boolean[][] visited) {
int count = 0;
Deque<int[]> stack = new ArrayDeque<>();
stack.addLast(new int[]{i, j});
visited[i][j] = true;
while (!stack.isEmpty()) {
int[] top = stack.removeLast();
int curX = top[0];
int curY = top[1];
count++;
for (int[] direction : DIRECTIONS) {
int newX = curX + direction[0];
int newY = curY + direction[1];
if (inArea(newX, newY, rows, cols) && grid[newX][newY] == 1 && !visited[newX][newY]) {
stack.addLast(new int[]{newX, newY});
visited[newX][newY] = true;
}
}
}
return count;
}
private boolean inArea(int i, int j, int rows, int cols) {
return i >= 0 && i < rows && j >= 0 && j < cols;
}
}提示读者这部分所有的问题都可以使用广度优先遍历完成。
- 完成「力扣」第 130 题:被围绕的区域(中等);深度优先遍历、广度优先遍历、并查集。
- 完成「力扣」第 200 题:岛屿数量(中等):深度优先遍历、广度优先遍历、并查集;
- 完成「力扣」第 417 题:太平洋大西洋水流问题(中等):深度优先遍历、广度优先遍历;
- 完成「力扣」第 1020 题:飞地的数量(中等):方法同第 130 题,深度优先遍历、广度优先遍历;
- 完成「力扣」第 1254 题:统计封闭岛屿的数目(中等):深度优先遍历、广度优先遍历;
- 完成「力扣」第 1034 题:边框着色(中等):深度优先遍历、广度优先遍历;
- 完成「力扣」第 133 题:克隆图(中等):借助哈希表,使用深度优先遍历、广度优先遍历;
- 完成「剑指 Offer」第 13 题:机器人的运动范围(中等):深度优先遍历、广度优先遍历;
- 完成「力扣」第 529 题:扫雷问题(中等):深度优先遍历、广度优先遍历;
深度优先遍历是一种重要的算法设计思想,可以用于解决「力扣」上很多问题,熟练掌握「深度优先遍历」以及与之相关的「递归」、「分治」思想的应用是十分有帮助的。事实上,有一类问题需要「深度优先遍历」思想与「动态规划」思想的结合。
在动态规划问题里,有一类问题叫做「树形动态规划 DP」问题。这一类问题通常的解决的思路是:通过对树结构执行一次深度优先遍历,采用 后序遍历 的方式,一层一层向上传递信息,并且利用「无后效性」的思想(固定住一些状态,或者对当前维度进行升维)解决问题。即这一类问题通常采用「后序遍历」 + 「动态规划(无后效性)」的思路解决。
友情提示:「无后效性」是「动态规划」的一个重要特征,也是一个问题可以使用「动态规划」解决的必要条件,「无后效性」就是字面意思:当前阶段的状态值一旦被计算出来就不会被修改,即:在计算之后阶段的状态值时不会修改之前阶段的状态值。
利用「无后效性」解决动态规划问题通常有两种表现形式:
对当前维度进行「升维」,在「自底向上递推」的过程中记录更多的信息,避免复杂的分类讨论;
固定住一种的状态,通常这种状态的形式最简单,它可以组合成复杂的状态。
理解「无后效性」需要做一些经典的使用「动态规划」解决的问题。例如:「力扣」第 62 题、第 120 题、第 53 题、第 152 题、第 300 题、第 1142 题。
「力扣」第 543 题:二叉树的直径(简单)
给定一棵二叉树,你需要计算它的直径长度。一棵二叉树的直径长度是任意两个结点路径长度中的最大值。这条路径可能穿过也可能不穿过根结点。
示例:
给定二叉树
1 / \ 2 3 / \ 4 5返回 3, 它的长度是路径
[4, 2, 1, 3]或者[5, 2, 1, 3]。注意:两结点之间的路径长度是以它们之间边的数目表示。
思路分析:
- 首先理解题意。在题目最后的「注意」中有强调:两个结点之间边的数目为直径,而不是结点的数目;
- 要了解树当中的信息,通常来说需要执行一次 深度优先遍历,最后在根结点汇总值,自底向上,一层一层向上汇报信息,这是 后序遍历;
- 我们再看直径的概念,题目中已经强调了:直径可能穿过也可能不穿过根结点。并且示例给出的路径 [4, 2, 1, 3] 或者 [5, 2, 1, 3] 是弯曲的,不是「从根结点到叶子结点的最长路径」,因此一条路径是否经过某个结点,就需要分类讨论。在动态规划里,可以利用一个概念,叫做「无后效性」,即:将不确定的事情确定下来,以方便以后的讨论。
我们采用逐步完善代码的方式向大家展示编码过程,首先写出代码大致的框架,请大家留意代码中的注释,注释体现了编码的思路。
public class Solution {
public int diameterOfBinaryTree(TreeNode root) {
dfs(root);
return res;
}
/**
* @param node 某个子树的根结点
* @return 必需经过当前 node 结点的「单边」路径长度的「最大值」,这是动态规划「无后效性」的应用
*/
private int dfs(TreeNode node) {
// 递归终止条件
if (node == null) {
return 0;
}
// 根据左右子树的结果,再得到当前结点的结果,这是典型的「后序遍历」的思想
int left = dfs(node.left);
int right = dfs(node.right);
// 注意:递归函数的返回值的定义,必需经过 node 并且只有一边
return Math.max(left, right) + 1;
}
}注意:这里递归函数 dfs 的定义,有两点很重要:① 必需经过当前 node 结点,也就是说当前结点 node 必需被选取,这一点是我们上面向大家介绍的「固定住」一些信息,方便分类讨论;② 「单边路径」是我们为了方便说明这个问题引入的概念。「单边路径」指的是 node 作为某一条路径的端点,它或者是「左端点」或者是「右端点」,它一定不是位于在这条路径中间的结点。
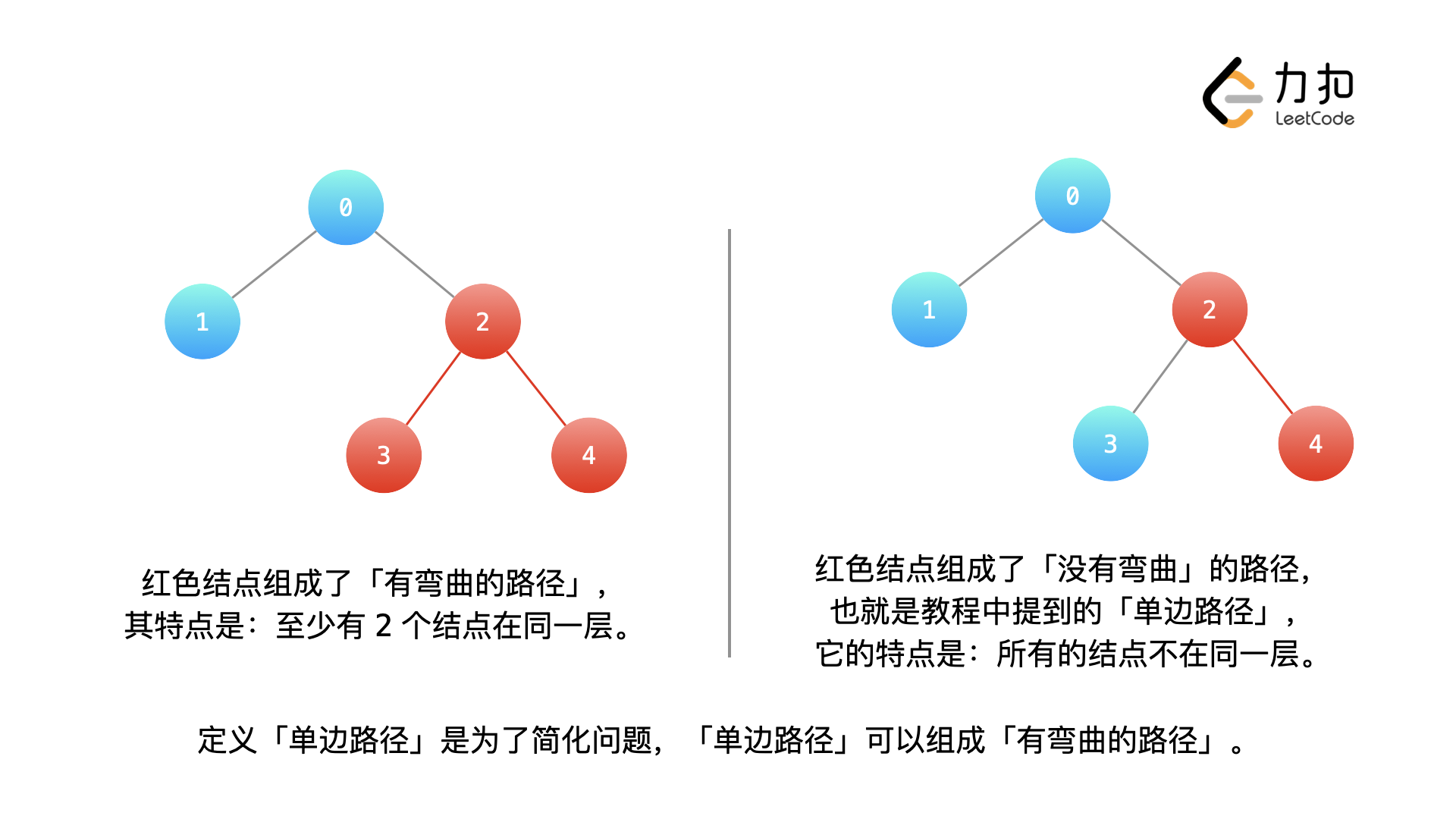
比较难理解的地方是:为什么只讨论「单边路径」?这是因为「单边」的情况最简单,是可以拆分的最小单元。「弯曲」的情况可以由「单边」的情况组合而成。
题目要求的直径,可以「弯曲」。「弯曲」的部分就是「左边单边」的长度 + 「右边单边」的长度之和,可以在遍历的过程中记录最大值。
public class Solution {
private int res;
public int diameterOfBinaryTree(TreeNode root) {
dfs(root);
return res;
}
/**
* @param node
* @return 必需经过当前 node 结点的路径长度的「最大值」
*/
private int dfs(TreeNode node) {
if (node == null) {
return 0;
}
int left = dfs(node.left);
int right = dfs(node.right);
// 注意:在深度优先遍历的过程中,记录最大值
res = Math.max(res, left + right);
return Math.max(left, right) + 1;
}
}- 完成「力扣」第 124 题:二叉树中的最大路径和(困难);
- 完成「力扣」第 298 题:二叉树最长连续序列(中等);
- 完成「力扣」第 549 题:二叉树中最长的连续序列(中等);
- 完成「力扣」第 687 题:最长同值路径(中等);
- 完成「力扣」第 865 题:具有所有最深节点的最小子树(中等);
- 完成「力扣」第 1372 题:二叉树中的最长交错路径(中等)。
下面的问题可以使用「二分答案 + DFS 或者 BFS」的思想解决。
- 完成「力扣」第 1102 题:得分最高的路径(中等);
- 完成「力扣」第 1631 题:最小体力消耗路径(中等);
- 完成「力扣」第 778 题:水位上升的泳池中游泳(困难);
- 完成「力扣」第 403 题:青蛙过河(困难)。
- 深度优先遍历的直观理解非常重要,支撑深度优先遍历实现的数据结构是「栈」;
- 「力扣」上很多树和图的问题都可以通过深度优先遍历实现、使用深度优先遍历实现的问题很多时候也可以使用广度优先遍历实现;
- 「回溯算法」是深度优先遍历算法的应用;
- 「回溯算法」的细节很多,需要通过练习和调试理解。