

文章目录:
- 什么是递归
什么是递归
递归的基本思想是某个函数直接或者间接地调用自身,这样就把原问题的求解转换为许多性质相同但是规模更小的子问题。我们只需要关注如何把原问题划分成符合条件的子问题,而不需要去研究这个子问题是如何被解决的。递归和枚举的区别在于:枚举是横向地把问题划分,然后依次求解子问题,而递归是把问题逐级分解,是纵向的拆分。
简单地说,就是如果在函数中存在着调用函数本身的情况,这种现象就叫递归。
你以前肯定写过递归,只是不知道这就是递归罢了。

以阶乘函数为例,如下, 在 factorial 函数中存在着 factorial(n - 1) 的调用,所以此函数是递归函数
public int factorial(int n) {
if (n < =1) {
return1;
}
return n * factorial(n - 1)
}
int fibonacci(int n) {
// Base case
if (n == 0 || n == 1) return n;
// Recursive step
return fibonacci(n-1) + fibonacci(n-2);
}
进一步剖析「递归」,先有「递」再有「归」,「递」的意思是将问题拆解成子问题来解决, 子问题再拆解成子子问题,...,直到被拆解的子问题无需再拆分成更细的子问题(即可以求解),「归」是说最小的子问题解决了,那么它的上一层子问题也就解决了,上一层的子问题解决了,上上层子问题自然也就解决了,....,直到最开始的问题解决,文字说可能有点抽象,那我们就以阶层 f(6) 为例来看下它的「递」和「归」。
求解问题 f(6), 由于 f(6) = n * f(5), 所以 f(6) 需要拆解成 f(5) 子问题进行求解,同理 f(5) = n * f(4) ,也需要进一步拆分,... ,直到 f(1), 这是「递」,f(1) 解决了,由于 f(2) = 2 f(1) = 2 也解决了,.... f(n)到最后也解决了,这是「归」,所以递归的本质是能把问题拆分成具有相同解决思路的子问题,。。。直到最后被拆解的子问题再也不能拆分,解决了最小粒度可求解的子问题后,在「归」的过程中自然顺其自然地解决了最开始的问题。
递归原理
递归是一种解决问题的有效方法,在递归过程中,函数将自身作为子例程调用
你可能想知道如何实现调用自身的函数。诀窍在于,每当递归函数调用自身时,它都会将给定的问题拆解为子问题。递归调用继续进行,直到到子问题无需进一步递归就可以解决的地步。
为了确保递归函数不会导致无限循环,它应具有以下属性:
- 一个简单的
基本案例(basic case)(或一些案例) —— 能够不使用递归来产生答案的终止方案。 - 一组规则,也称作
递推关系(recurrence relation),可将所有其他情况拆分到基本案例。
注意,函数可能会有多个位置进行自我调用。
递归的基本思想是某个函数直接或者间接地调用自身,这样就把原问题的求解转换为许多性质相同但是规模更小的子问题。我们只需要关注如何把原问题划分成符合条件的子问题,而不需要去研究这个子问题是如何被解决的。递归和枚举的区别在于:枚举是横向地把问题划分,然后依次求解子问题,而递归是把问题逐级分解,是纵向的拆分。
递归代码最重要的两个特征:结束条件和自我调用。自我调用是在解决子问题,而结束条件定义了最简子问题的答案。
int func(你今年几岁) {
// 最简子问题,结束条件
if (你1999年几岁) return 我0岁;
// 自我调用,缩小规模
return func(你去年几岁) + 1;
}
编写一个函数,其作用是将输入的字符串反转过来。输入字符串以字符数组
char[]的形式给出。不要给另外的数组分配额外的空间,你必须原地修改输入数组、使用 O(1) 的额外空间解决这一问题。
你可以假设数组中的所有字符都是 ASCII 码表中的可打印字符。
示例 1:
输入:["h","e","l","l","o"] 输出:["o","l","l","e","h"]
递归实在计算机科学、数学等领域运用非常广泛的一种方法。使用递归的方法解决问题,一般具有这样的特征:我们在寻找一个复杂问题的解时,不能立即给出答案,然后从一个规模较小的相同问题的答案开始,却可以较为容易的求解复杂的问题。
我们主要介绍两种基于递归的算法设计技术,即基于归纳的递归和分治法。
递归(recursion)是指在定义自身的同时又出现了对自身的引用。如果一个算法直接或间接的调用自己,则称这个算法是一个递归算法。
递归算法的实质是把问题分解成规模缩小的同类问题的子问题,然后递归调用方法来表示问题的解。
任何一个有意义的递归算法总是两部分组成:递归调用和递归终止条件。
递归是一种应用非常广泛的算法或者编程技巧。很多数据结构和算法的编码实现都要用到递归,比如DFS深度优先搜索、前中后序二叉树遍历等等。所以搞懂递归对学习一些复杂的数据结构和算法是非常有必要的。
案例:周末带着女朋友去电影院看电影,女朋友问,咱们现在坐在第几排啊?电影院里面太黑了,看不清,没法数,现在怎么办?
于是你就问前面一排的人他是第几排,你想只要在他的数字上加一,就知道自己在哪一排了。但是,前面的人也看不清啊,所以他也问他前面的人。就这样一排一排往前问,直到问到第一排的人,说我在第一排,然后再这样一排一排再把数字传回来。直到你前面的人告诉你他在哪一排,于是你就知道答案了。
这就是一个非常标准的递归求解问题的分解过程,去的过程叫“递”,回来的过程叫“归”。
基本上,所有的递归问题都可以用递推公式来表示。比如上面的案例我们用递推公式将它表示出来就是这样:
f(n) = f(n-1) + 1 //其中 f(1) = 1
f(n) 表示想知道自己在哪一排,f(n-1) 表示前面一排所在的排数,f(1) = 1表示第一排的人知道自己在第一排。有了这个递推公式,我们就可以很轻松地将它改为递归代码:
int f(int n) {
if (n == 1) return 1;
return f(n - 1) + 1;
}
只要同时满足以下三个条件,就可以用递归来解决。
-
一个问题的解可以分解为几个子问题的解
何为子问题?子问题就是数据规模更小的问题。比如前面的案例,要知道“自己在哪一排”,可以分解为“前一排的人在哪一排”这样的一个子问题。
-
这个问题与分解之后的子问题,除了数据规模不同,求解思路完全一样
如案例所示,求解“自己在哪一排”的思路,和前面一排人求解“自己在哪一排”的思路是一模一样的。
-
存在递归终止条件
把问题分解为子问题,把子问题再分解为子子问题,一层一层分解下去,不能存在无限循环,这就需要有终止条件。前面的案例:第一排的人知道自己在哪一排,不需要再问别人,f(1) = 1就是递归的终止条件。
写递归代码,可以按三步走:
第一要素:明确你这个函数想要干什么
对于递归,我觉得很重要的一个事就是,这个函数的功能是什么,他要完成什么样的一件事,而这个,是完全由你自己来定义的。也就是说,我们先不管函数里面的代码什么,而是要先明白,你这个函数是要用来干什么。
例如,我定义了一个函数
// 算 n 的阶乘(假设n不为0)
int f(int n){
}
这个函数的功能是算 n 的阶乘。好了,我们已经定义了一个函数,并且定义了它的功能是什么,接下来我们看第二要素。
第二要素:寻找递归结束条件
所谓递归,就是会在函数内部代码中,调用这个函数本身,所以,我们必须要找出递归的结束条件,不然的话,会一直调用自己,进入无底洞。也就是说,我们需要找出当参数为啥时,递归结束,之后直接把结果返回,请注意,这个时候我们必须能根据这个参数的值,能够直接知道函数的结果是什么。
例如,上面那个例子,当 n = 1 时,那你应该能够直接知道 f(n) 是啥吧?此时,f(1) = 1。完善我们函数内部的代码,把第二要素加进代码里面,如下
// 算 n 的阶乘(假设n不为0)
int f(int n){
if(n == 1){
return 1;
}
}
有人可能会说,当 n = 2 时,那我们可以直接知道 f(n) 等于多少啊,那我可以把 n = 2 作为递归的结束条件吗?
当然可以,只要你觉得参数是什么时,你能够直接知道函数的结果,那么你就可以把这个参数作为结束的条件,所以下面这段代码也是可以的。
// 算 n 的阶乘(假设n>=2)
int f(int n){
if(n == 2){
return 2;
}
}
注意我代码里面写的注释,假设 n >= 2,因为如果 n = 1时,会被漏掉,当 n <= 2时,f(n) = n,所以为了更加严谨,我们可以写成这样:
// 算 n 的阶乘(假设n不为0)
int f(int n){
if(n <= 2){
return n;
}
}
第三要素:找出函数的等价关系式
第三要素就是,我们要不断缩小参数的范围,缩小之后,我们可以通过一些辅助的变量或者操作,使原函数的结果不变。
例如,f(n) 这个范围比较大,我们可以让 f(n) = n * f(n-1)。这样,范围就由 n 变成了 n-1 了,范围变小了,并且为了原函数f(n) 不变,我们需要让 f(n-1) 乘以 n。
说白了,就是要找到原函数的一个等价关系式,f(n) 的等价关系式为 n * f(n-1),即
f(n) = n * f(n-1)。
写递归代码最关键的是写出递推公式,找到终止条件,剩下就是将递推公式转化为代码。
案例:假如这里有 n 个台阶,每次你可以跨 1 个台阶或者 2 个台阶,请问走这 n 个台阶有多少种走法?如果有 7 个台阶,你可以 2,2,2,1 这样子上去,也可以 1,2,1,1,2 这样子上去,总之走法有很多,那如何用编程求得总共有多少种走法呢?
我们可以根据第一步的走法把所有走法分为两类,第一类是第一步走了1个台阶,另一类是第一步走了2个台阶。所以n个台阶的走法就等于先走1阶后,n-1个台阶的走法 加上先走2阶后,n-2个台阶的走法,用公式表示:
f(n) = f(n-1) + f(n-2)
再来看下终止条件。当有一个台阶时,我们不需要再继续递归,就只有一种走法。所以f(1) = 1。这个递归终止条件足够吗?我们试试用n = 2, n = 3这样比较小的数实验一下。
n = 2时,f(2) = f(1) + f(0)。如果递归终止条件只有一个f(1) = 1,那f(2)就无法求解了。所以除了f(1) = 1这一个递归终止条件外,还要有f(0) = 1,表示走0个台阶有一种走法,不过这样看起来不符合正常的逻辑思维。所以,我们可以把f(2) = 2作为一种终止条件,表示走2个台阶,只有两种走法,一步走完或者分两步走。
所以,递归终止条件就是f(1) = 1,f(2) = 2。这个时候,可以再拿n = 3,n = 4来验证下,这个终止条件是否足够并且正确。
我们把递归终止条件和刚刚得到的递推公式放在一起就是这样:
f(1) = 1;
f(2) = 2;
f(n) = f(n - 1) + f(n - 2);
最终的递归代码就是这样:
int f(int n) {
if (n == 1) return 1;
if (n == 2) return 2;
return f(n -1) + f(n - 2);
}
写递归代码的关键就是找到如何将大问题分解为小问题的规律,请求基于此写出递推公式,然后再推敲终止条件,最后将递推公式和终止条件翻译成代码。
当我们面对一个问题需要分解为多个子问题的时候,递归代码往往没那么好理解,比如第二个案例,人脑几乎没办法把整个“递”和“归”的过程一步一步都想清楚。
计算机擅长做重复的事情,所以递归正符合它的胃口。而我们人脑更喜欢平铺直叙的思维方式。当我们看到递归时,我们总想把递归平铺展开,脑子里就会循环,一层一层往下调,然后再一层一层返回,试图想搞清楚计算机每一步都是怎么执行的,这样就很容易被绕进去。
对于递归代码,这种试图想清楚整个递和归过程的做法,实际上是进入了一个思维误区。很多时候,我们理解起来比较吃力,主要原因就是自己给自己制造了这种理解障碍。那正确的思维方式应该是怎样的呢?
如果一个问题 A 可以分解为若干子问题 B、C、D,可以假设子问题 B、C、D 已经解决,在此基础上思考如何解决问题 A。而且,只需要思考问题 A 与子问题 B、C、D 两层之间的关系即可,不需要一层一层往下思考子问题与子子问题,子子问题与子子子问题之间的关系。屏蔽掉递归细节,这样子理解起来就简单多了。
换句话说就是:千万不要跳进这个函数里面企图探究更多细节,否则就会陷入无穷的细节无法自拔,人脑能压几个栈啊。
所以,编写递归代码的关键是:只要遇到递归,我们就把它抽象成一个递推公式,不用想一层层的调用关系,不要试图用人脑去分解递归的每个步骤。
在实际开发中,编写递归代码我们通常会遇到很多问题,比如堆栈溢出。而堆栈溢出会造成系统性崩溃,后果非常严重。为什么递归代码容易造成堆栈溢出呢?
我们知道在函数调用时,会使用栈来保存临时变量。每调用一个函数,都会将临时变量封装为栈帧压入内存栈,等函数执行完成返回时,才出栈。系统栈或者虚拟机栈空间一般都不大。如果递归求解的数据规模很大,调用层次很深,一直压入栈,就会有堆栈溢出的风险,出现java.lang.StackOverflowError。
如何避免出现堆栈溢出?
可以通过在代码中限制递归调用的最大深度的方式来解决这个问题。递归调用超过一定深度(比如1000)之后,我们就不再继续往下递归了,直接返回报错。比如前面电影院的案例,改造后的伪代码如下:
// 全局变量,表示递归的深度。
int depth = 0;
int f(int n) {
++depth;
if (depth > 1000) throw exception;
if (n == 1) return 1;
return f(n-1) + 1;
}但这种做法并不能完全解决问题,因为最大允许的递归深度跟当前线程剩余的栈空间大小有关,事先无法计算。如果实时计算,代码又会过于复杂,影响到代码的可读性。所以如果最大深度比较小,比如10、50,还可以用这种方法,否则这种方法不是很实用。
使用递归时要注意重复计算的问题,比如案例二,我们把整个递归过程分解一下,那就是这样的:
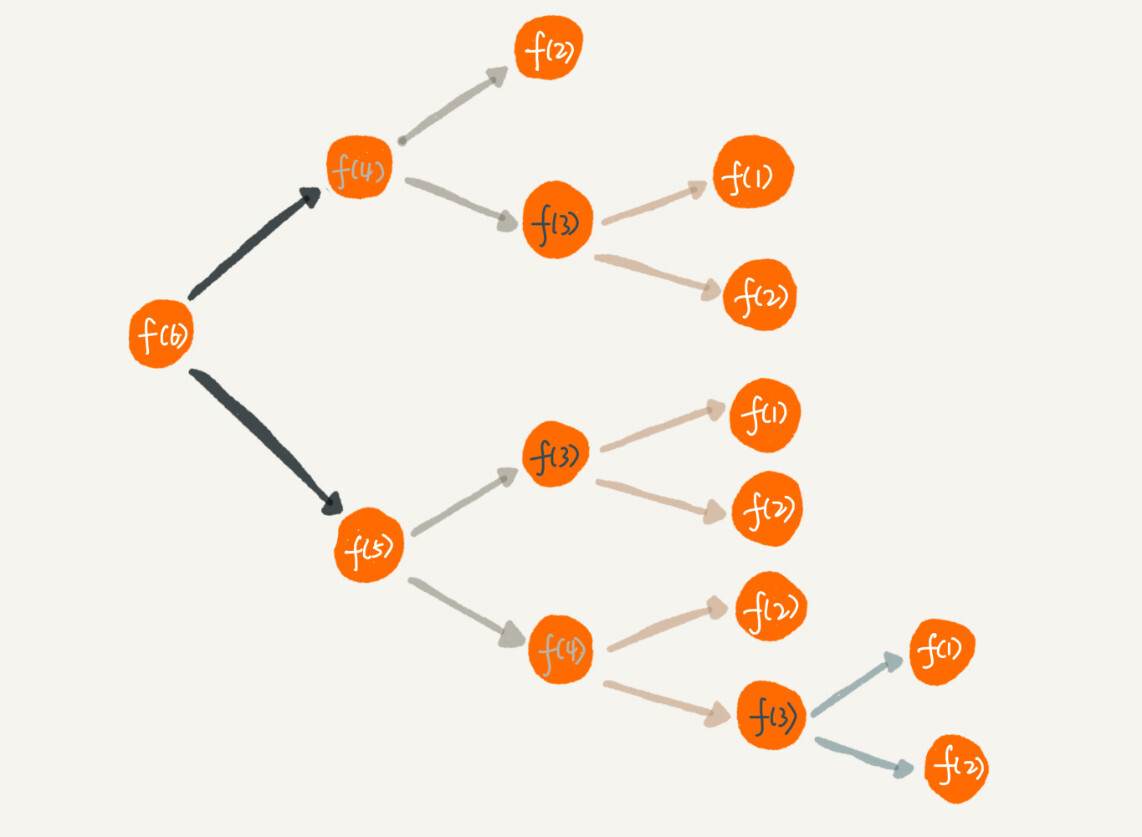
从图中,我们可以看到,想要计算f(5),需要先计算f(4)和f(3),而计算f(4)还需要计算f(3),因此,f(3)就被计算了很多次,这就是重复计算的问题。
为了解决重复计算,我们可以通过散列表等数据结构来保存已经求解过的f(k)。当递归调用到f(k)时,先看下是否已经求解过了。如果是,则直接从散列表中取值返回,就不再重复计算了。
如上思路,改造下刚才的代码:
public int f(int n) {
if (n == 1) return 1;
if (n == 2) return 2;
// hasSolvedList 可以理解成一个 Map,key 是 n,value 是 f(n)
if (hasSolvedList.containsKey(n)) {
return hasSovledList.get(n);
}
int ret = f(n-1) + f(n-2);
hasSovledList.put(n, ret);
return ret;
}
除了堆栈溢出、重复计算这两个常见的问题,递归代码还有很多别的问题。
在时间效率上,递归代码里多了很多函数调用,当这些函数调用的数量较大时,就会积累成一个可观的时间成本。在空间复杂度上,因为递归调用一次就会在内存栈中保存一次现场数据,所以在分析递归代码空间复杂度时,需要额外考虑这部分的开销,比如前面的案例一的递归代码,空间复杂度并不是O(1),而是O(n)。
斐波那契数列的是这样一个数列:1、1、2、3、5、8、13、21、34....,即第一项 f(1) = 1,第二项 f(2) = 1.....,第 n 项目为 f(n) = f(n-1) + f(n-2)。求第 n 项的值是多少。
1、第一递归函数功能
假设 f(n) 的功能是求第 n 项的值,代码如下:
int f(int n){
}
2、找出递归结束的条件
显然,当 n = 1 或者 n = 2 ,我们可以轻易着知道结果 f(1) = f(2) = 1。所以递归结束条件可以为 n <= 2。代码如下:
int f(int n){
if(n <= 2){
return 1;
}
}
第三要素:找出函数的等价关系式
题目已经把等价关系式给我们了,所以我们很容易就能够知道 f(n) = f(n-1) + f(n-2)。我说过,等价关系式是最难找的一个,而这个题目却把关系式给我们了,这也太容易,好吧,我这是为了兼顾几乎零基础的读者。
所以最终代码如下:
int f(int n){
// 1.先写递归结束条件
if(n <= 2){
return 1;
}
// 2.接着写等价关系式
return f(n-1) + f(n - 2);
}
搞定,是不是很简单?
一只青蛙一次可以跳上1级台阶,也可以跳上2级。求该青蛙跳上一个n级的台阶总共有多少种跳法。
1、第一递归函数功能
假设 f(n) 的功能是求青蛙跳上一个n级的台阶总共有多少种跳法,代码如下:
int f(int n){
}
2、找出递归结束的条件
我说了,求递归结束的条件,你直接把 n 压缩到很小很小就行了,因为 n 越小,我们就越容易直观着算出 f(n) 的多少,所以当 n = 1时,你知道 f(1) 为多少吧?够直观吧?即 f(1) = 1。代码如下:
int f(int n){
if(n == 1){
return 1;
}
}
第三要素:找出函数的等价关系式
每次跳的时候,小青蛙可以跳一个台阶,也可以跳两个台阶,也就是说,每次跳的时候,小青蛙有两种跳法。
第一种跳法:第一次我跳了一个台阶,那么还剩下n-1个台阶还没跳,剩下的n-1个台阶的跳法有f(n-1)种。
第二种跳法:第一次跳了两个台阶,那么还剩下n-2个台阶还没,剩下的n-2个台阶的跳法有f(n-2)种。
所以,小青蛙的全部跳法就是这两种跳法之和了,即 f(n) = f(n-1) + f(n-2)。至此,等价关系式就求出来了。于是写出代码:
int f(int n){
if(n == 1){
return 1;
}
ruturn f(n-1) + f(n-2);
}
大家觉得上面的代码对不对?
答是不大对,当 n = 2 时,显然会有 f(2) = f(1) + f(0)。我们知道,f(0) = 0,按道理是递归结束,不用继续往下调用的,但我们上面的代码逻辑中,会继续调用 f(0) = f(-1) + f(-2)。这会导致无限调用,进入死循环。
这也是我要和你们说的,关于递归结束条件是否够严谨问题,有很多人在使用递归的时候,由于结束条件不够严谨,导致出现死循环。也就是说,当我们在第二步找出了一个递归结束条件的时候,可以把结束条件写进代码,然后进行第三步,但是请注意,当我们第三步找出等价函数之后,还得再返回去第二步,根据第三步函数的调用关系,会不会出现一些漏掉的结束条件。就像上面,f(n-2)这个函数的调用,有可能出现 f(0) 的情况,导致死循环,所以我们把它补上。代码如下:
int f(int n){
//f(0) = 0,f(1) = 1,等价于 n<=1时,f(n) = n。
if(n <= 1){
return n;
}
ruturn f(n-1) + f(n-2);
}
有人可能会说,我不知道我的结束条件有没有漏掉怎么办?别怕,多练几道就知道怎么办了。
看到这里有人可能要吐槽了,这两道题也太容易了吧??能不能被这么敷衍。少侠,别走啊,下面出道难一点的。
反转单链表。例如链表为:1->2->3->4。反转后为 4->3->2->1
链表的节点定义如下:
class Node{
int date;
Node next;
}
虽然是 Java语言,但就算你没学过 Java,我觉得也是影响不大,能看懂。
还是老套路,三要素一步一步来。
1、定义递归函数功能
假设函数 reverseList(head) 的功能是反转但链表,其中 head 表示链表的头节点。代码如下:
Node reverseList(Node head){
}
2. 寻找结束条件
当链表只有一个节点,或者如果是空表的话,你应该知道结果吧?直接啥也不用干,直接把 head 返回呗。代码如下:
Node reverseList(Node head){
if(head == null || head.next == null){
return head;
}
}
3. 寻找等价关系
这个的等价关系不像 n 是个数值那样,比较容易寻找。但是我告诉你,它的等价条件中,一定是范围不断在缩小,对于链表来说,就是链表的节点个数不断在变小,所以,如果你实在找不出,你就先对 reverseList(head.next) 递归走一遍,看看结果是咋样的。例如链表节点如下
我们就缩小范围,先对 2->3->4递归下试试,即代码如下
Node reverseList(Node head){
if(head == null || head.next == null){
return head;
}
// 我们先把递归的结果保存起来,先不返回,因为我们还不清楚这样递归是对还是错。,
Node newList = reverseList(head.next);
}
我们在第一步的时候,就已经定义了 reverseLis t函数的功能可以把一个单链表反转,所以,我们对 2->3->4反转之后的结果应该是这样:
我们把 2->3->4 递归成 4->3->2。不过,1 这个节点我们并没有去碰它,所以 1 的 next 节点仍然是连接这 2。
接下来呢?该怎么办?
其实,接下来就简单了,我们接下来只需要把节点 2 的 next 指向 1,然后把 1 的 next 指向 null,不就行了?,即通过改变 newList 链表之后的结果如下:
也就是说,reverseList(head) 等价于 ** reverseList(head.next)** + 改变一下1,2两个节点的指向。好了,等价关系找出来了,代码如下(有详细的解释):
//用递归的方法反转链表
public static Node reverseList2(Node head){
// 1.递归结束条件
if (head == null || head.next == null) {
return head;
}
// 递归反转 子链表
Node newList = reverseList2(head.next);
// 改变 1,2节点的指向。
// 通过 head.next获取节点2
Node t1 = head.next;
// 让 2 的 next 指向 2
t1.next = head;
// 1 的 next 指向 null.
head.next = null;
// 把调整之后的链表返回。
return newList;
}
这道题的第三步看的很懵?正常,因为你做的太少了,可能没有想到还可以这样,多练几道就可以了。但是,我希望通过这三道题,给了你以后用递归做题时的一些思路,你以后做题可以按照我这个模式去想。通过一篇文章是不可能掌握递归的,还得多练,我相信,只要你认真看我的这篇文章,多看几次,一定能找到一些思路!!
我已经强调了好多次,多练几道了,所以呢,后面我也会找大概 10 道递归的练习题供大家学习,不过,我找的可能会有一定的难度。不会像今天这样,比较简单,所以呢,初学者还得自己多去找题练练,相信我,掌握了递归,你的思维抽象能力会更强!
接下来我讲讲有关递归的一些优化。
1. 考虑是否重复计算
告诉你吧,如果你使用递归的时候不进行优化,是有非常非常非常多的子问题被重复计算的。
啥是子问题? f(n-1),f(n-2)....就是 f(n) 的子问题了。
例如对于案例2那道题,f(n) = f(n-1) + f(n-2)。递归调用的状态图如下:
看到没有,递归计算的时候,重复计算了两次 f(5),五次 f(4)。。。。这是非常恐怖的,n 越大,重复计算的就越多,所以我们必须进行优化。
如何优化?一般我们可以把我们计算的结果保证起来,例如把 f(4) 的计算结果保证起来,当再次要计算 f(4) 的时候,我们先判断一下,之前是否计算过,如果计算过,直接把 f(4) 的结果取出来就可以了,没有计算过的话,再递归计算。
用什么保存呢?可以用数组或者 HashMap 保存,我们用数组来保存把,把 n 作为我们的数组下标,f(n) 作为值,例如 arr[n] = f(n)。f(n) 还没有计算过的时候,我们让 arr[n] 等于一个特殊值,例如 arr[n] = -1。
当我们要判断的时候,如果 arr[n] = -1,则证明 f(n) 没有计算过,否则, f(n) 就已经计算过了,且 f(n) = arr[n]。直接把值取出来就行了。代码如下:
// 我们实现假定 arr 数组已经初始化好的了。
int f(int n){
if(n <= 1){
return n;
}
//先判断有没计算过
if(arr[n] != -1){
//计算过,直接返回
return arr[n];
}else{
// 没有计算过,递归计算,并且把结果保存到 arr数组里
arr[n] = f(n-1) + f(n-1);
reutrn arr[n];
}
}
也就是说,使用递归的时候,必要 须要考虑有没有重复计算,如果重复计算了,一定要把计算过的状态保存起来。
2. 考虑是否可以自底向上
对于递归的问题,我们一般都是从上往下递归的,直到递归到最底,再一层一层着把值返回。
不过,有时候当 n 比较大的时候,例如当 n = 10000 时,那么必须要往下递归10000层直到 n <=1 才将结果慢慢返回,如果n太大的话,可能栈空间会不够用。
对于这种情况,其实我们是可以考虑自底向上的做法的。例如我知道
f(1) = 1;
f(2) = 2;
那么我们就可以推出 f(3) = f(2) + f(1) = 3。从而可以推出f(4),f(5)等直到f(n)。因此,我们可以考虑使用自底向上的方法来取代递归,代码如下:
public int f(int n) {
if(n <= 2)
return n;
int f1 = 1;
int f2 = 2;
int sum = 0;
for (int i = 3; i <= n; i++) {
sum = f1 + f2;
f1 = f2;
f2 = sum;
}
return sum;
}
这种方法,其实也被称之为递推。
来源: