DFS(深度优先搜索)和 BFS(广度优先搜索)就像孪生兄弟,提到一个总是想起另一个。然而在实际使用中,我们用 DFS 的时候远远多于 BFS。那么,是不是 BFS 就没有什么用呢?
如果我们使用 DFS/BFS 只是为了遍历一棵树、一张图上的所有结点的话,那么 DFS 和 BFS 的能力没什么差别,我们当然更倾向于更方便写、空间复杂度更低的 DFS 遍历。不过,某些使用场景是 DFS 做不到的,只能使用 BFS 遍历。
DFS 遍历使用递归:
void dfs(TreeNode root) { if (root == null) { return; } dfs(root.left); dfs(root.right); }BFS 遍历使用队列数据结构:
void bfs(TreeNode root) { Queue<TreeNode> queue = new ArrayDeque<>(); queue.add(root); while (!queue.isEmpty()) { TreeNode node = queue.poll(); // Java 的 pop 写作 poll() if (node.left != null) { queue.add(node.left); } if (node.right != null) { queue.add(node.right); } } }只是比较两段代码的话,最直观的感受就是:DFS 遍历的代码比 BFS 简洁太多了!这是因为递归的方式隐含地使用了系统的 栈,我们不需要自己维护一个数据结构。如果只是简单地将二叉树遍历一遍,那么 DFS 显然是更方便的选择。
虽然 DFS 与 BFS 都是将二叉树的所有结点遍历了一遍,但它们遍历结点的顺序不同。
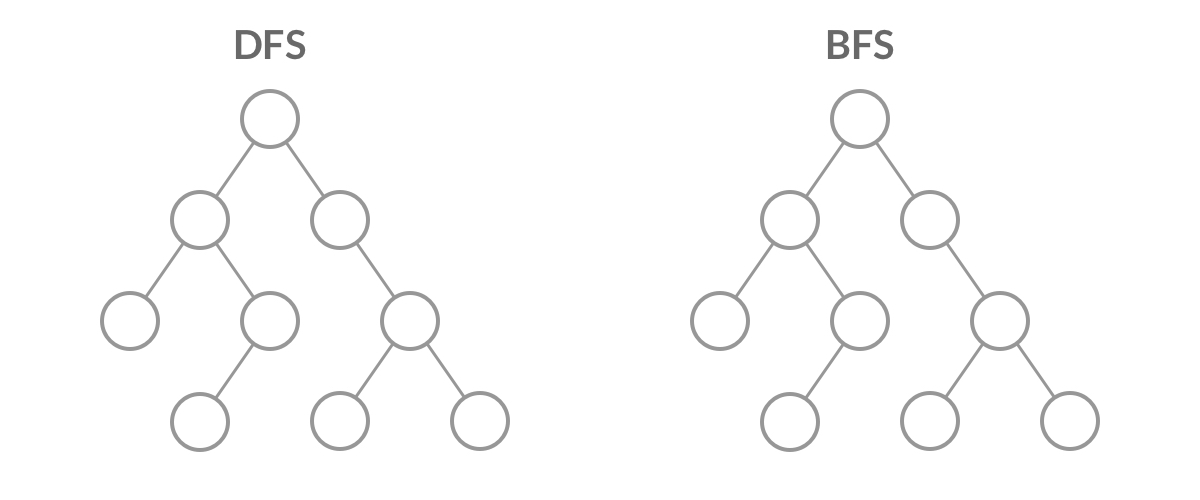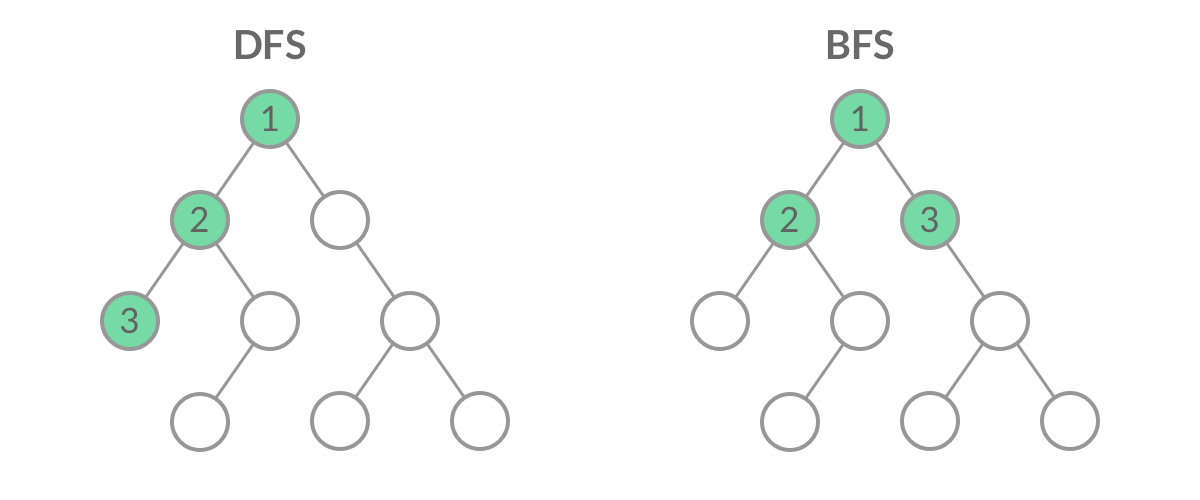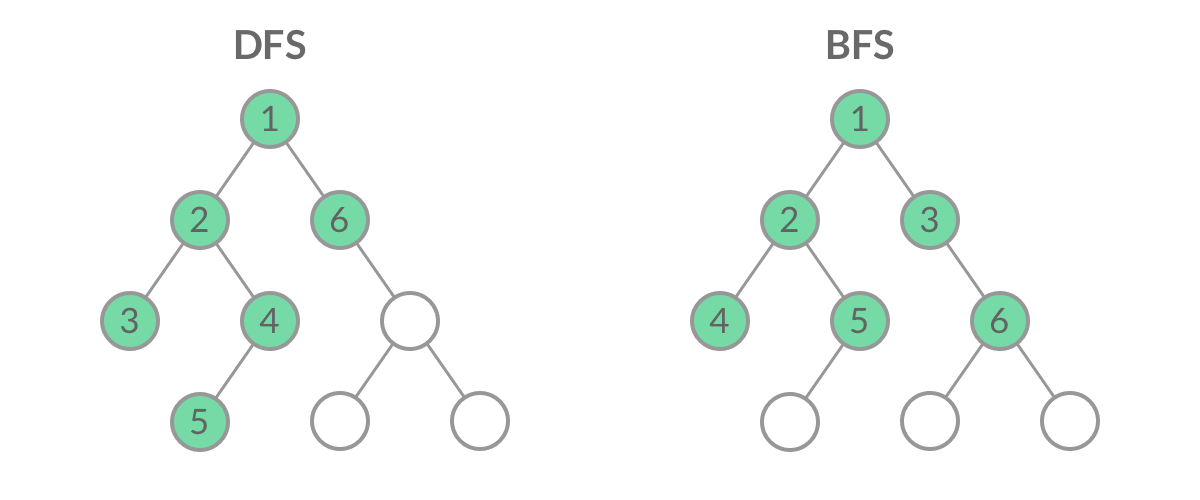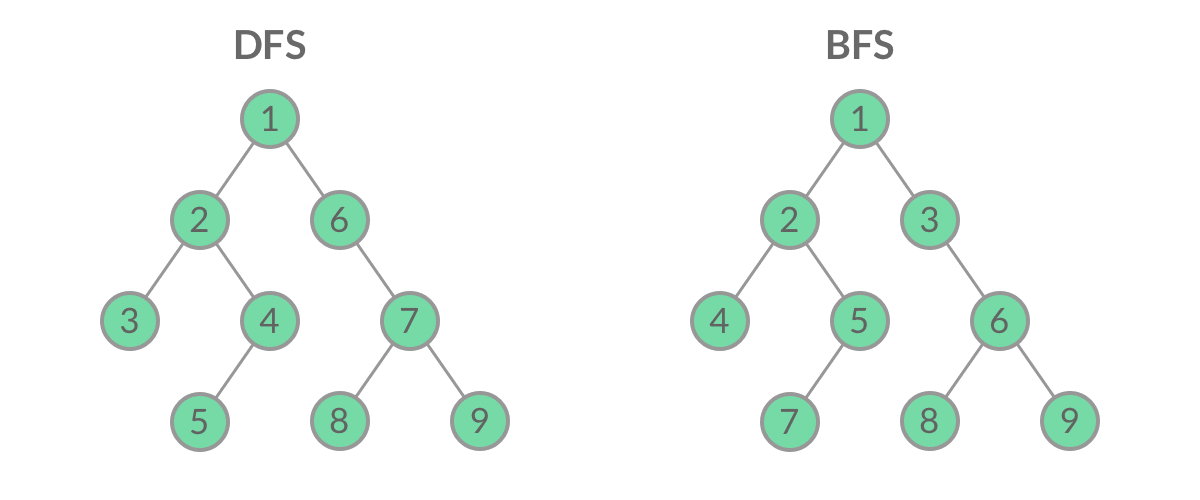
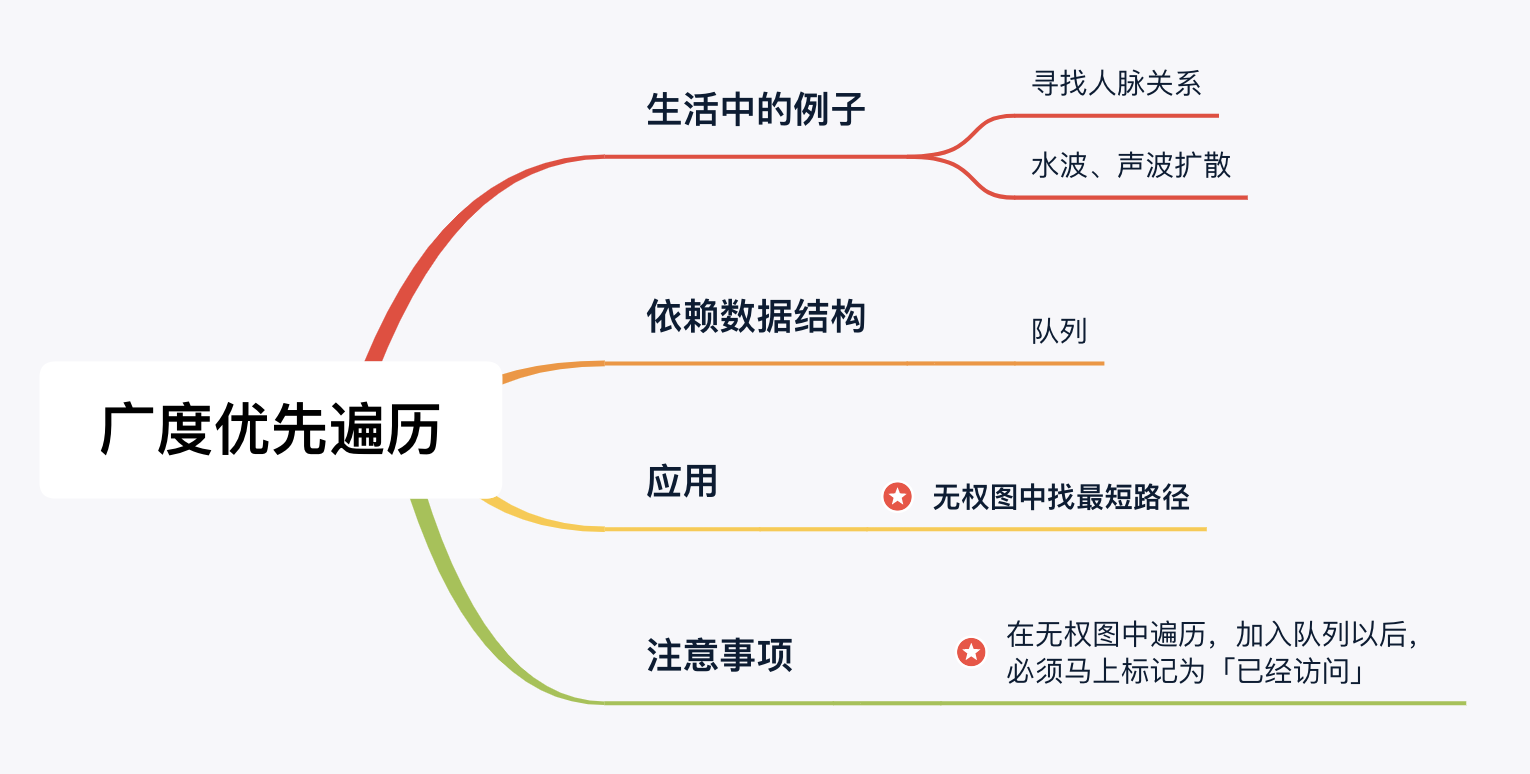
「广度优先遍历」的思想在生活中随处可见:
如果我们要找一个医生或者律师,我们会先在自己的一度人脉中遍历(查找),如果没有找到,继续在自己的二度人脉中遍历(查找),直到找到为止。
广度优先遍历呈现出「一层一层向外扩张」的特点,先看到的结点先遍历,后看到的结点后遍历,因此「广度优先遍历」可以借助「队列」实现。
说明:遍历到一个结点时,如果这个结点有左(右)孩子结点,依次将它们加入队列。
友情提示:广度优先遍历的写法相对固定,我们不建议大家背代码、记模板。在深刻理解广度优先遍历的应用场景(找无权图的最短路径),借助「队列」实现的基础上,多做练习,写对代码就是自然而然的事情了
我们先介绍「树」的广度优先遍历,再介绍「图」的广度优先遍历。事实上,它们是非常像的。
例 1:「力扣」第 102 题:二叉树的层序遍历(中等)
给你一个二叉树,请你返回其按 层序遍历 得到的节点值。 (即逐层地,从左到右访问所有节点)。
示例:
二叉树:[3,9,20,null,null,15,7],
3 / \ 9 20 / \ 15 7返回其层序遍历结果:
[ [3], [9,20], [15,7] ]
思路分析:
-
题目要求我们一层一层输出树的结点的值,很明显需要使用「广度优先遍历」实现;
-
广度优先遍历借助「队列」实现;
-
注意:
- 这样写 for (int i = 0; i < queue.size(); i++) { 代码是不能通过测评的,这是因为 queue.size() 在循环中是变量(这条规则在 Python 中不成立,请各位读者自行验证)。正确的做法是:每一次在队列中取出元素的个数须要先暂存起来,请见参考代码;
- 子结点入队的时候,非空的判断很重要:在队列的队首元素出队的时候,一定要在左(右)子结点非空的时候才将左(右)子结点入队。
-
树的广度优先遍历的写法模式相对固定:
- 使用队列;
- 在队列非空的时候,动态取出队首元素;
- 取出队首元素的时候,把队首元素相邻的结点(非空)加入队列。
大家在做题的过程中需要多加练习,融汇贯通,不须要死记硬背。
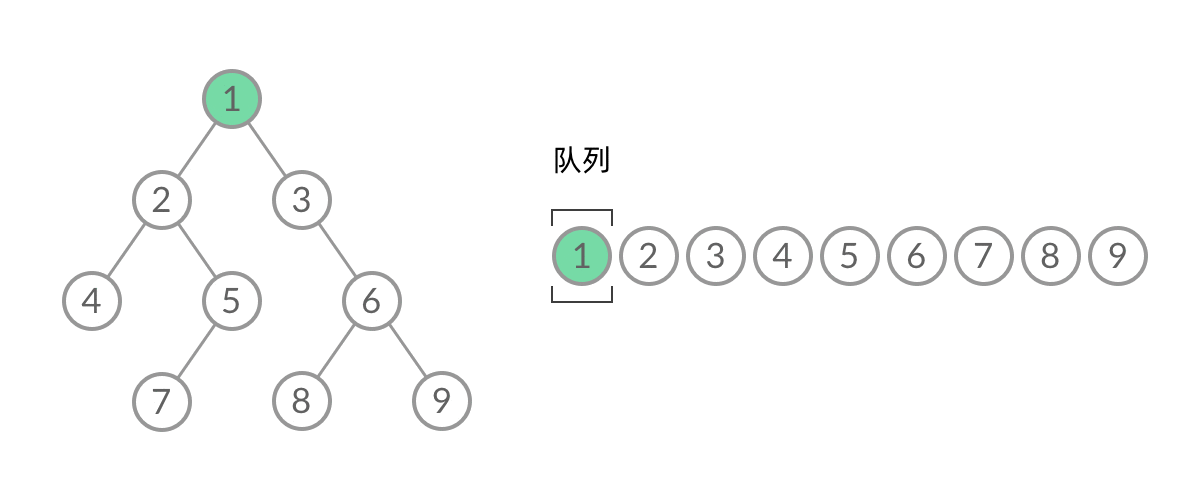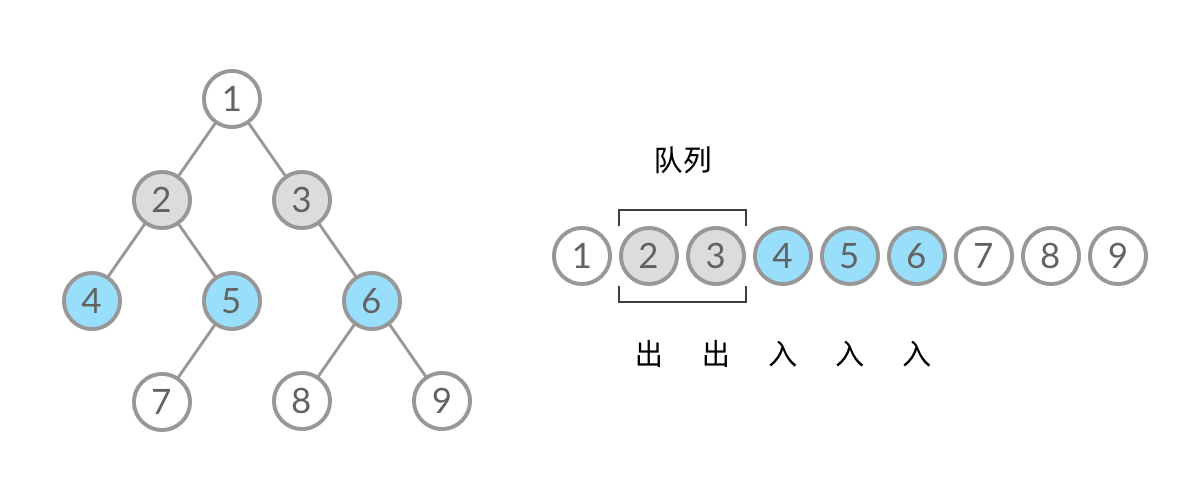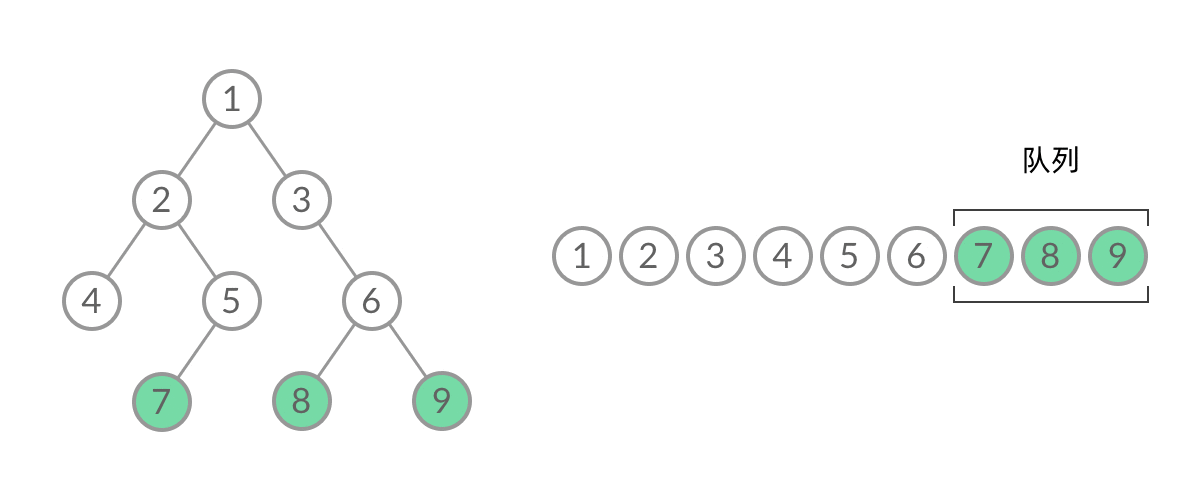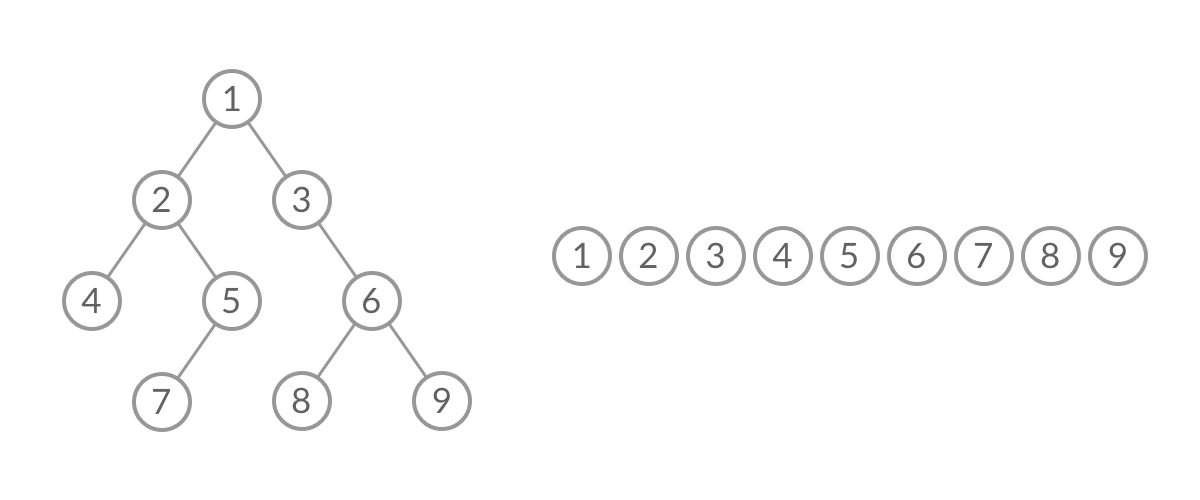
public class Solution {
public List<List<Integer>> levelOrder(TreeNode root) {
List<List<Integer>> res = new ArrayList<>();
if (root == null) {
return res;
}
Queue<TreeNode> queue = new LinkedList<>();
queue.offer(root);
while (!queue.isEmpty()) {
// 注意 1:一定要先把当前队列的结点总数暂存起来
int currentSize = queue.size();
List<Integer> currentLevel = new ArrayList<>();
for (int i = 0; i < currentSize; i++) {
TreeNode front = queue.poll();
currentLevel.add(front.val);
// 注意 2:左(右)孩子结点非空才加入队列
if (front.left != null) {
queue.offer(front.left);
}
if (front.right != null) {
queue.offer(front.right);
}
}
res.add(currentLevel);
}
return res;
}
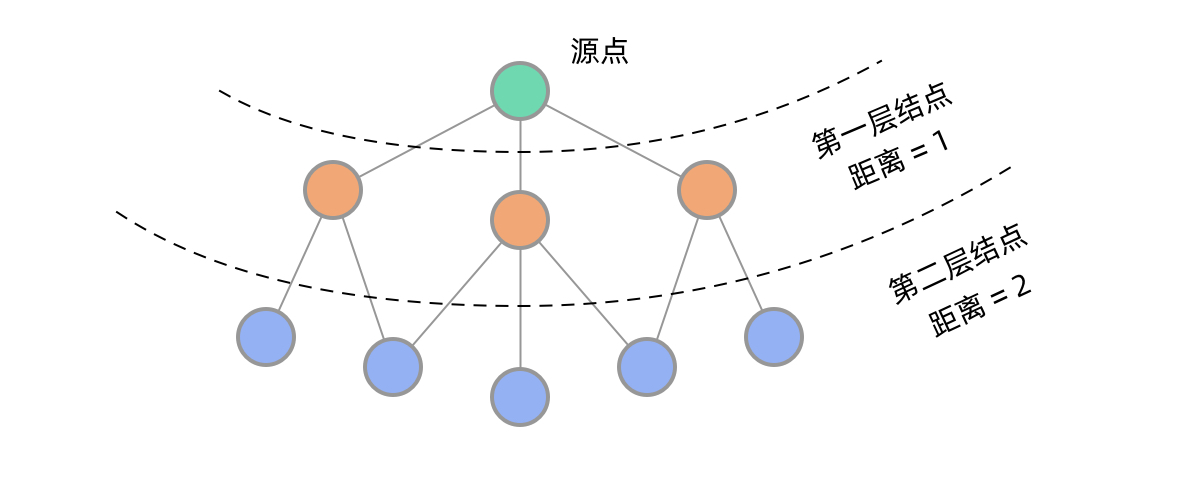
}在 无权图 中,由于广度优先遍历本身的特点,假设源点为 source,只有在遍历到 所有 距离源点 source 的距离为 d 的所有结点以后,才能遍历到所有 距离源点 source 的距离为 d + 1 的所有结点。也可以使用「两点之间、线段最短」这条经验来辅助理解如下结论:从源点 source 到目标结点 target 走直线走过的路径一定是最短的。
在一棵树中,一个结点到另一个结点的路径是唯一的,但在图中,结点之间可能有多条路径,其中哪条路最近呢?这一类问题称为最短路径问题。最短路径问题也是 BFS 的典型应用,而且其方法与层序遍历关系密切。
在二叉树中,BFS 可以实现一层一层的遍历。在图中同样如此。从源点出发,BFS 首先遍历到第一层结点,到源点的距离为 1,然后遍历到第二层结点,到源点的距离为 2…… 可以看到,用 BFS 的话,距离源点更近的点会先被遍历到,这样就能找到到某个点的最短路径了。
小贴士:
很多同学一看到「最短路径」,就条件反射地想到「Dijkstra 算法」。为什么 BFS 遍历也能找到最短路径呢?
这是因为,Dijkstra 算法解决的是带权最短路径问题,而我们这里关注的是无权最短路径问题。也可以看成每条边的权重都是 1。这样的最短路径问题,用 BFS 求解就行了。
在面试中,你可能更希望写 BFS 而不是 Dijkstra。毕竟,敢保证自己能写对 Dijkstra 算法的人不多。
最短路径问题属于图算法。由于图的表示和描述比较复杂,本文用比较简单的网格结构代替。网格结构是一种特殊的图,它的表示和遍历都比较简单,适合作为练习题。在 LeetCode 中,最短路径问题也以网格结构为主。
在图中,由于 图中存在环,和深度优先遍历一样,广度优先遍历也需要在遍历的时候记录已经遍历过的结点。特别注意:将结点添加到队列以后,一定要马上标记为「已经访问」,否则相同结点会重复入队,这一点在初学的时候很容易忽略。如果很难理解这样做的必要性,建议大家在代码中打印出队列中的元素进行调试:在图中,如果入队的时候不马上标记为「已访问」,相同的结点会重复入队,这是不对的。
另外一点还需要强调,广度优先遍历用于求解「无权图」的最短路径,因此一定要认清「无权图」这个前提条件。如果是带权图,就需要使用相应的专门的算法去解决它们。事实上,这些「专门」的算法的思想也都基于「广度优先遍历」的思想,我们为大家例举如下:
-
带权有向图、且所有权重都非负的单源最短路径问题:使用 Dijkstra 算法;
-
带权有向图的单源最短路径问题:Bellman-Ford 算法;
-
一个图的所有结点对的最短路径问题:Floy-Warshall 算法。
这里列出的以三位计算机科学家的名字命名的算法,大家可以在《算法导论》这本经典著作的第 24 章、第 25 章找到相关知识的介绍。值得说明的是:应用任何一种算法,都需要认清使用算法的前提,不满足前提直接套用算法是不可取的。深刻理解应用算法的前提,也是学习算法的重要方法。例如我们在学习「二分查找」算法、「滑动窗口」算法的时候,就可以问自己,这个问题为什么可以使用「二分查找」,为什么可以使用「滑动窗口」。我们知道一个问题可以使用「优先队列」解决,是什么样的需求促使我们想到使用「优先队列」,而不是「红黑树(平衡二叉搜索树)」,想清楚使用算法(数据结构)的前提更重要。
「力扣」第 323 题:无向图中连通分量的数目(中等)
友情提示:第 1 - 4 题是广度优先遍历的变形问题,写对这些问题有助于掌握广度优先遍历的代码编写逻辑和细节。
- 完成「力扣」第 107 题:二叉树的层次遍历 II(简单);
- 完成《剑指 Offer》第 32 - I 题:从上到下打印二叉树(中等);
- 完成《剑指 Offer》第 32 - III 题:从上到下打印二叉树 III(中等);
- 完成「力扣」第 103 题:二叉树的锯齿形层次遍历(中等);
- 完成「力扣」第 429 题:N 叉树的层序遍历(中等);
- 完成「力扣」第 993 题:二叉树的堂兄弟节点(中等);