这是本项目的记录文档,包括相关知识的学习笔记、对于该项目各周期的进度记录,以及讨论的汇总。
在与Prof Gao讨论之后,我的 Master Project 就是要将 RLR Tree 实现到 PostgresSQL 中。首先需要深入理解 RTree,以及 RLR Tree 的实现思路。
R-Tree 是 RLR Tree 的基础,它是于 1984 年由 Guttman 提出来的,主要用于空间搜索。以下的笔记参考的材料有:
- Introduction to R-Tree
- The R-Tree: A dynamic index structure for spatial searching
- R-Tree: algorithm for efficient indexing of spatial data
R-Tree 是用于对高维数据和地理数据 (例如坐标和矩形) 进行有效地存取,它的特点是只有一个根结点,而且子节点指向的内容完全包含在父节点的范围中。而只有叶子结点才真正包含指向的对象的内容,这里的数据对象指的是一个闭区间的

搜索目标对象
这里的目标对象指的就是图1中的实线矩形,搜索算法会自顶向下地遍历每个结点,检查它是否完全包含目标矩形。如果是,就选中它的子节点继续遍历。该算法的问题是一个结点下需要搜索多个子树,如果树的高度特别高,时间就会很长,难以度量最差的表现。
更新 R-Tree
CondenseTree: 在删除结点时触发。当数据对象被删掉后,该算法检查对应的叶子结点是否仍有
AdjustTree: 在插入结点时触发。如果插入后,当前结点的指针数 >
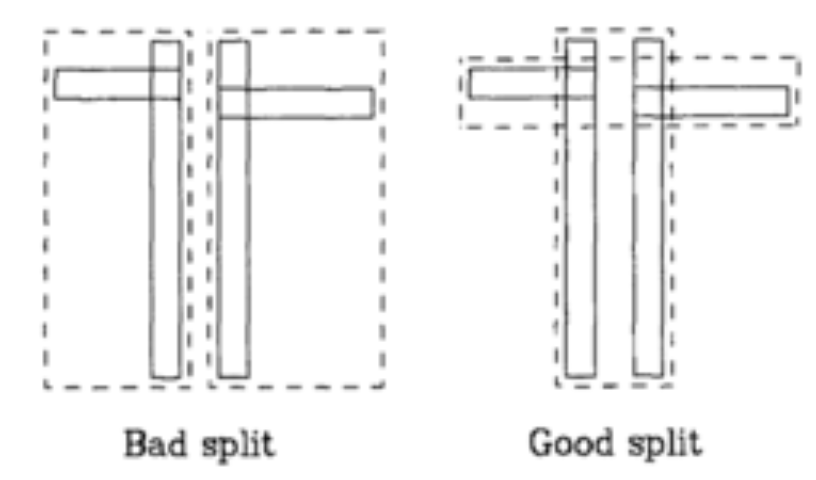
结点切分
切分结点的方法有两种:
-
线性复杂度切分
从
$Q$ 中选取距离最远的两个点分别作为新分组的头元素,然后将剩余的点随机分配至新分组中 -
平方复杂度切分
从
$Q$ 中选取所能张成的最大区域的两个区域作为新分组的头元素
将该篇论文的要点整理如下:
| Title | A Reinforcement Learning Based R-Tree for Spatial Data Indexing in Dynamic Environments |
|---|---|
| Author | TuGu, GaoCong @ NTU |
| Year | 2021 |
| Prerequisite | R-Tree, 1984, Recursive Model Index, 2018@MIT, |
| Motivation | 1. 使用 learned indices 替换传统的索引结构 (e.g B-Tree) 往往能够取得不错的性能表现; 2. 但是这需要完全替换原有的结构和查询算法,遇到了很多实现上的困难; 3. 本文想在不改变索引结构的情况下,采用基于 RL 的方法,提高空间查找的效率。 |
| Current Challenge | 1. 现有 R-tree 的各种 insert 和 split 操作得到的索引树在查询的速度上,都没有显著的优势; 2. 将 ChooseSubTree 和 Split 操作形式化为两个连续的 MDP 是相当困难的,如何定义每个过程的状态、动作和奖励信号呢? 3. 难以使用 RL 来找到最优的过程,因为当前的 good action 可能会由于之前的 bad action 而得到惩罚值。 |
| Related Work | 1. Learned Index - data and query limited; - not accurate; - cannot handle updates, or need to periodic rebuild. - replace index structure and query algorithm 2. Heuristic Strategies used in R-Tree - no single index outperforms the others |
| Method | 通过基于 RL 的模型,确定如何建立 R-Tree 具体地,这是通过将 insert 和 split 操作形式化为两个连续的 MDP,再使用 RL 来最优化。这就需要定义 MDP 的 state, action, reward signal, transition. 1. State 对每个结点的子节点进行遍历,选取前 2. Action 类似的,选取当前结点的 3. Reward Signal 设计 1 个 reference tree (RT),将所要插入的对象同时插入到 RT 和 RLR-Tree 中,以两者的结点访问率 (node access rate) 的差作为激励信号。 |
| Baseline | |
| Highlight | |
| Future Challenge | |
| Relevant Work | 1. The "AI+R"-tree: An Instance-optimized R-tree: 将原有的数据库查找操作变为多标签分类任务; 2. |
在 PostgreSQL 8.4.1 中支持的索引有:B-Tree 索引、Hash 索引、GiST 索引和 GIN 索引。
PostgreSQL: BTree-implementation
🔍如何实现一个索引?
- 把树的结构写出来,确定它所有接口的 API;
- 链接到数据库的操作中。
- 索引如何存储?
Postgres Indexes Under the Hood
Branching Factor 的选取
就是一个结点最多能容纳的数据元素的个数
B-Trees are extremely shallow data structures. Because the branching factor is typically in the thousands, they can store millions of elements in only 2-3 layers. When used in a database, this means only 2-3 disk seeks are required to find any given item, greatly improving performance over the dozens of seeks required for a comparable on-disk binary search tree or similar data structure.
Typical branching factors will be between a few hundred to a few thousand items per page.
Specification
-
Postgres nodes have a fixed amount of bytes
If you have variable-size data, each node in your index will actually have a different number of children
-
Highr key allows concurrency
The “high-key” pointer allows readers to detect that this split has occurred: If you’re looking for a value greater than the high key, you must follow the right-link! The right link allows the reader to traverse directly to the newly split node where the key now resides.
Implementation of GiST indexing for Postgres
【参考材料1】The GiST Indexing Project
GiST (Generalized Search Tree) 称为通用搜索树,它为各种类型的索引树 (R-trees, B+-trees, hB-trees, TV-trees, Ch-Trees 等) 都提供了一个统一的接口,允许用户在任意数据类型上进行索引。除此之外,GiST 还具有数据和 查询的可拓展性。
📕 查询的可拓展性
这里指用于可以在 GiST 中自定义查询谓词。以前的搜索树在其处理的数据方面是可扩展的。例如,POSTGRES支持可扩展的B+树和R树。这意味着你可以使用POSTGRES在任何你想要的数据类型上建立一个B+树或R树。但是 B+ 树只支持范围谓词(<, = >),而 R 树只支持
$[n, d]$ 范围查询(包含、包含、相等)。因此,如果你用 POSTGRES B+ 树来索引,比如说,一堆电影,你只能提出类似 "查找所有 < T2 的电影 "的查询。虽然这个查询可能有意义(例如,小于可能意味着价格不那么贵、评分不那么高),但这样的写法并不显然。相反,你想问的是关于电影的特定查询,比如 "找到所有有爆炸场面的电影","找到所有有吴京的电影",或者 "找到所有有摩托车追逐的电影"。这样的查询在 B+ 树、R 树或者除了 GiST 之外的任何其他已知结构中都无法直接支持。相比之下,你可以通过编程让 GiST 支持任何查询谓词,包括上面提到的
爆炸场面和其他谓词。要让 GiST 启动和运行,只需要实现 4 个用户定义的方法,这些方法定义了树中键的行为。当然,这些方法会是非常复杂的,来支持复杂的查询。但对于所有的标准查询(如 B- 树、R- 树等),就不需要这些了。简而言之,GiST 结合了新的可扩展性、通用性、代码重用和一个漂亮的简洁界面。
由于 B-Tree 处理的是数值型、R-Tree 是 Bounding Box,这种统一性就意味着 GiST 的 key 是独特的。它的 Key 是由用户自定义的类的成员,并且可以通过判断它的某些属性来使得键的指针能够指向所有的 item,即支持类似于小于操作的属性。
Key 的 Class 的实现
以下给出了用于键的用户自定义的 class 需要实现的 4 个接口:
-
Consistent: This method lets the tree search correctly. Given a key p on a tree page, and user query q, the Consistent method should return NO if it is certain that both p and q cannot be true for a given data item. Otherwise it should return MAYBE.
? p 为 true 的含义是什么
-
Union: This method consolidates information in the tree. Given a set S of entries, this method returns a new key p which is true for all the data items below S. A simple way to implement Union is to return a predicate equivalent to the disjunction of the keys in S, i.e. "p1 or p2 or p3 or...".
-
Penalty: Given a choice of inserting a new data item in a subtree rooted by entry <p, ptr>, return a number representing how bad it would be to do that. Items will get inserted down the path of least Penalty in the tree.
-
PickSplit: As in a B-tree, pages in a GiST occasionally need to be split upon insertion of a new data item. This routine is responsible for deciding which items go to the new page, and which ones stay on the old page.
There are some optional additional methods that can enhance performance. These are described in the original paper on the data structure.
而对于索引项的增删改查,GiST 已经内置实现了,但这恰恰是本项目需要修改的地方。本项目应当是通过使用与索引项管理相关的 7 种方法,实现:
- 索引的创建
gistbuild; - 索引项的插入
gistdoinsert; - 索引的查询
gistnext.
首先,我要了解 R-Tree 是如何进行增删的,我找到了Delete a Node from BST, 可以在有空的时候练一练。不过我的重点还是应该在看论文,了解这个模型的架构。因为对于这些增删改查的操作,这篇论文是使用了基于 RL 的方法,不要求先学懂传统的增删的方法。
- implement and integrate into DBMSs
- Generalized Search Tree (GiST), a “template” index structure supporting an extensible set of queries and datatypes.
- Why generalized search tree can support extensible queries?
Python docs: Extending Python with C++
RLR-Tree 代码仓库中包含了 6 个 Python 文件和 2 个 C 文件,定义了 R-Tree 的结构及接口、从给定的数据集中构建树的过程、KNN 查询测试方法、范围查询测试方法、RL 选择子树策略的实现、RL 分裂结点策略的实现等过程。下面将每一个文件的作用及依赖关系给出。
数据结构定义
-
RTree.cpp实现了
RTree.h中 RTree 的 insert, split, rangeQuery 等等操作 -
RTree.py依赖于 [1],对输入项稍加处理后,直接调用 [1] 中 C++ 对于 RTree 的实现
核心算法定义
-
model_ChooseSubtree.py依赖于 [2],定义了选择子树的 RL 算法
-
model_Split.py依赖于 [2],定义了分裂结点的 RL 算法
-
combined_model.py依赖于 [2],定义了交替训练选择子树和分裂结点的算法
测试过程定义
-
RTree_RRstar_test_cpp_KNN.py依赖于 [2],定义了 R-Tree 和 RRStar 使用 KNN 查询的测试过程
-
RTree_RRstar_test_cpp.py依赖于 [2],定义了 R-Tree 和 RRStar 使用范围查询的测试过程
-
main.cpp依赖于 [1],定义了读取数据集及测试 baseline 的方法
现在,需要确定的是:
- 能否把文件 [5] 迁移到 Gist 上,也就是基于 [5] 修改 Gist 中ChooseSubtree 和 Split 的 API。也就是修改
gistdoInsert; - 训练与推断过程 (Python 实现的) 如何迁移到 PSQL (C++ 实现的)上面。是在这两个之间建一个接口,还是使用 PSql 的框架重新实现一遍。
在确定完当前的工作后,我看了 Gist 的实现代码,找到了其中要修改的文件之一 gistsplit.c。它有 700 多行,而且从注释上看,它与硬盘中的 page 紧密相关,我对其中 picksplit, column 的含义都一无所知,完全看不懂它在干什么。因此,还是有必要先看懂 Gist 的理论基础 Concurrency and Recovery in Generalized Search Trees,再看代码实现。
🔍 如何高效阅读源码
高效地阅读源码要求我们自顶向下地看这个项目,先了解业务流程,再理清执行流程,最后再深入到代码的每一行中。具体地,在需要阅读一个较大项目 (e.g 由多个文件组成,总代码行数 > 5k) 前,需要先充分了解这个代码的业务逻辑,即要解决什么问题、有哪些功能、数据怎么交互的。接下来,把代码跑起来,各种功能都用一下,了解他的执行逻辑(这里可以画出代码执行的流程图)。最后,再开始看源码,这样会容易上手很多。
GiST 的作者在Generalized Search Trees for Database Systems介绍了 GiST 提出的背景、特点、与 B+树 和 R 树的不同、数据结构、实现方法、性能分析,同时作者还回顾了数据库中索引树的基本思想并强调了某些细节。这篇文章非常适合入门,对于后续理解索引树中的并行及 R 树的代码非常重要。
由于传统的索引树如 B+ 树、R 树,只能提供内置的 predicate (如比较数字的大小、范围查询),并且需要存储数据的 key 满足相应的条件,因此可延展性不够好。于是就有伯克利的学者提出更具延展性的索引树 GiST (Generalized Search Tree)。它支持用户自定义 predicate,只需要实现作者指定的 6 个方法即可。
这六个方法包括与查询相关的 predicate 定义的 4 个方法,以及与树结构调整相关的 2 个方法。对于本项目,应当重点看后者的两个方法:
-
$Penalty(E_1, E_2):$ 给定两个结点$E_1, E_2$ ,返回将$E_2$ 插入到以$E_1$ 为根的子树中的 cost。例如在 R-Tree 中,这里的 cost 指的就是插入后$E_2$ 后,$E_1$ 包围盒的增量; -
$PickSplit(P):$ 给定一个包含$M+1$ 个结点的集合$P$ ,返回将$P$ 划分为两个集合$(P_1, P_2)$ 的最佳方案。
在作者提出的 ChooseSubTree(3) 和 Split(3) 算法中,使用到的外部函数有且仅有上述两个方法。
🚩 **目标 1: ** 将上述两个函数,以文件 [5] 中的方法实现即可。
看 PostgeSQL 中 RTree 的代码,它的 ChooseSubTree() 是不是仅仅基于 penalty() 这个外部方法。如果是的话,基于文件 [5] 实现 penalty 即可。
它调用的是 gistState->penaltyFn[],而对 penalty 的定义是在 RelationData* index 中的。通过 gistStateInit() 函数,将对每个 key 的 penaltyFn 地址赋值到对应的 penaltyFn[] 数组中。
现在我下载了 libgist 这个仓库,它是 GiST 的 C++ 实现,但是还没有融入到 PostgreSQL 中,虽然这个里面有 example。所以,我还是决定直接对 PostgreSQL 进行 Debug,使用 VSCode build PSql 的源码、了解 GiST 在 PSql 的用法、调试指令,来深入地了解 PSql 的运行逻辑,从而对其进行修改。除此之外,这个源码中还有相当多涉及硬盘分页的知识,我还要深入的学习索引与物理内存、外存的对应关系。这个应当与并行的设计高度相关,所以我还要深入理解 Concurrency and Recovery in Generalized Search Trees.
🚩 **目标 1.1: 理解 GiST 的并行 调试 PSql 源码 深入理解 PSql 运行逻辑 **
在一个完整的数据库系统
The rest of this paper is organized as follows:
-
section 2 contains a brief description of the basic GiST structure
-
Why do we need GiST?
由于传统的索引树如 B+ 树、R 树,只能提供内置的 predicate (如比较数字的大小、范围查询),并且需要存储数据的 key 满足相应的条件,因此可延展性不够好。而且从 B 树的实现上来看,对于并行访问、事务隔离、异常恢复的支持使得代码变得异常的复杂,并且占据了代码的主要部分。真正实现一个 DBMS 中的索引树相当复杂。
于是就有伯克利的学者提出更具延展性的索引树 GiST (Generalized Search Tree)。它支持用户自定义 predicate,只需要实现作者指定的 6 个方法即可。而且不需要考虑并行访问、事务隔离等特性。
-
Why it can support extensible queries?
Because the predicates of GiST is user-difined, more specifically, the
consistent()method. When searching according to one given predicate, it just invokes this method to determine whether the given predicate is consistent with the current node. So, there is no restrictions on the queries. It can be range comparison like B-Tree, rectangle box containment like R-Tree, and so on. As long as you implement theconsistent(), it can then support the corresponding queries. -
What's the structure of GiST?
The GiST is a banlanced tree, with extensible data types and queries, and it commonly has a large fanout. The leaf node contains
$(key, RdI)$ pairs, with the record identifier pointing to the page the target data lies. While the internal node contains$(predicate, childPointer)$ pairs, where the predicate implies all the data items reachable from the subtree, thechildPoniterpoints.And this exactly captures the essence of a tree-based index structure: a hierarchy of predicates, in which each predicate holds true for all keys stored under it in the hierarchy.
-
How GiST search works?
-
How GiST insert works?
-
What is the difference between R-Tree and GiST
Aside from the extensible queries that only GiST supports, their tree structure is also a little bit different. Overlaps between predicate at the same level is allowed in the GiST, and the union of all these predicates may have "holes". While for the R-Tree, the value range distributed in each level is unique and contagious.
-
-
section 3 extends this structure for concurrent access
-
What does concurrent access mean?
-
How to make the original structure support concurrent access?
-
What's the implementaion difficulties?
,
-
-
section 4 outlines our design of the hybrid locking mechanism.
-
After these preliminaries, the subsequent four sections explain the algorithms for index lookup, key insertion into non-unique and unique indices and key deletion.
-
section 9: Logging and recovery
-
section 10: discusses a variety of implementation issues
-
section 11: discusses some of the implicationsof the structure of an access method for concurrency control techniques and explains why most of the prior work on B-trees cannot be directly applied in the GiST context
-
section 12 concludes this paper with a summary.
the Split operation may be propagated upwards