| title | MySQL 查询 | |
|---|---|---|
| date | 2023-03-31 | |
| tags |
|
|
| categories | MySQL |

SQL的全称是Structured Query Language,翻译后就是结构化查询语言。
在开发应用的时候,一定会经常碰到需要根据指定的字段排序来显示结果的需求。
CREATE TABLE `t` (
`id` int(11) NOT NULL,
`city` varchar(16) NOT NULL,
`name` varchar(16) NOT NULL,
`age` int(11) NOT NULL,
PRIMARY KEY (`id`),
KEY `city` (`city`)
) ENGINE=InnoDB;业务需求来了,

Extra 这个字段中的“Using filesort”表示的就是需要排序,MySQL 会给每个线程分配一块内存用于排序,称为 sort_buffer。
mysql> show variables like 'sort_buffer_size';
+------------------+--------+
| Variable_name | Value |
+------------------+--------+
| sort_buffer_size | 262144 |
+------------------+--------+
1 row in set (0.00 sec)这个语句的大概执行流程是这样的:
- 初始化 sort_buffer,确定放入 name、city、age 这三个字段;
- 从索引 city 找到第一个满足 city='北京’ 条件的主键 id;
- 到主键 id 索引取出整行,取 name、city、age 三个字段的值,存入 sort_buffer 中;
- 从索引 city 取下一个记录的主键 id;
- 重复步骤 3、4 直到 city 的值不满足查询条件为止;
- 对 sort_buffer 中的数据按照字段 name 做快速排序;
- 按照排序结果取前 3 行返回给客户端。
我们暂且把这个排序过程,称为『全字段排序』
“按 name 排序”这个动作,可能在内存中完成,也可能需要使用外部排序,这取决于排序所需的内存和参数 sort_buffer_size。
sort_buffer_size,就是 MySQL 为排序开辟的内存(sort_buffer)的大小。如果要排序的数据量小于 sort_buffer_size,排序就在内存中完成。但如果排序数据量太大,内存放不下,则不得不利用磁盘临时文件辅助排序。
在上面这个算法过程里面,只对原表的数据读了一遍,剩下的操作都是在 sort_buffer 和临时文件中执行的。但这个算法有一个问题,就是如果查询要返回的字段很多的话,那么 sort_buffer 里面要放的字段数太多,这样内存里能够同时放下的行数很少,要分成很多个临时文件,排序的性能会很差。
所以如果单行很大,这个方法效率不够好。
那么,如果 MySQL 认为排序的单行长度太大会怎么做呢?
接下来,我来修改一个参数,让 MySQL 采用另外一种算法。
SET max_length_for_sort_data = 16;max_length_for_sort_data,是 MySQL 中专门控制用于排序的行数据的长度的一个参数。它的意思是,如果单行的长度超过这个值,MySQL 就认为单行太大,要换一个算法。
city、name、age 这三个字段的定义总长度是 36,我把 max_length_for_sort_data 设置为 16,我们再来看看计算过程有什么改变。
新的算法放入 sort_buffer 的字段,只有要排序的列(即 name 字段)和主键 id。
但这时,排序的结果就因为少了 city 和 age 字段的值,不能直接返回了,整个执行流程就变成如下所示的样子:
- 初始化 sort_buffer,确定放入两个字段,即 name 和 id;
- 从索引 city 找到第一个满足 city='杭州’条件的主键 id;
- 到主键 id 索引取出整行,取 name、id 这两个字段,存入 sort_buffer 中;
- 从索引 city 取下一个记录的主键 id;
- 重复步骤 3、4 直到不满足 city='杭州’条件为止;
- 对 sort_buffer 中的数据按照字段 name 进行排序;
- 遍历排序结果,取前 3 行,并按照 id 的值回到原表中取出 city、name 和 age 三个字段返回给客户端。
对全字段排序流程你会发现,rowid 排序多访问了一次表 t 的主键索引,就是步骤 7。
如果 MySQL 实在是担心排序内存太小,会影响排序效率,才会采用 rowid 排序算法,这样排序过程中一次可以排序更多行,但是需要再回到原表去取数据。
如果 MySQL 认为内存足够大,会优先选择全字段排序,把需要的字段都放到 sort_buffer 中,这样排序后就会直接从内存里面返回查询结果了,不用再回到原表去取数据。
这也就体现了 MySQL 的一个设计思想:如果内存够,就要多利用内存,尽量减少磁盘访问。
当然,如果我们创建了覆盖索引,就不需要再排序了
alter table t add index city_user_age(city, name, age);
-
手写
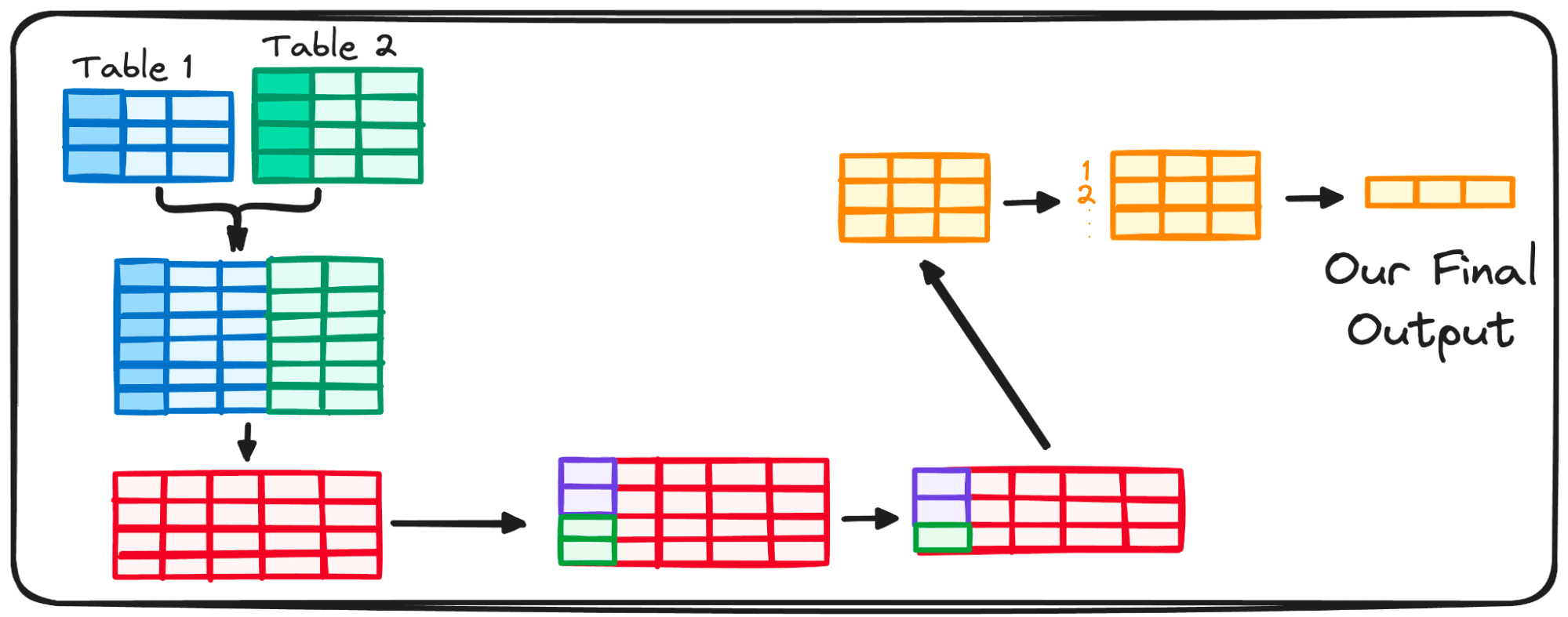
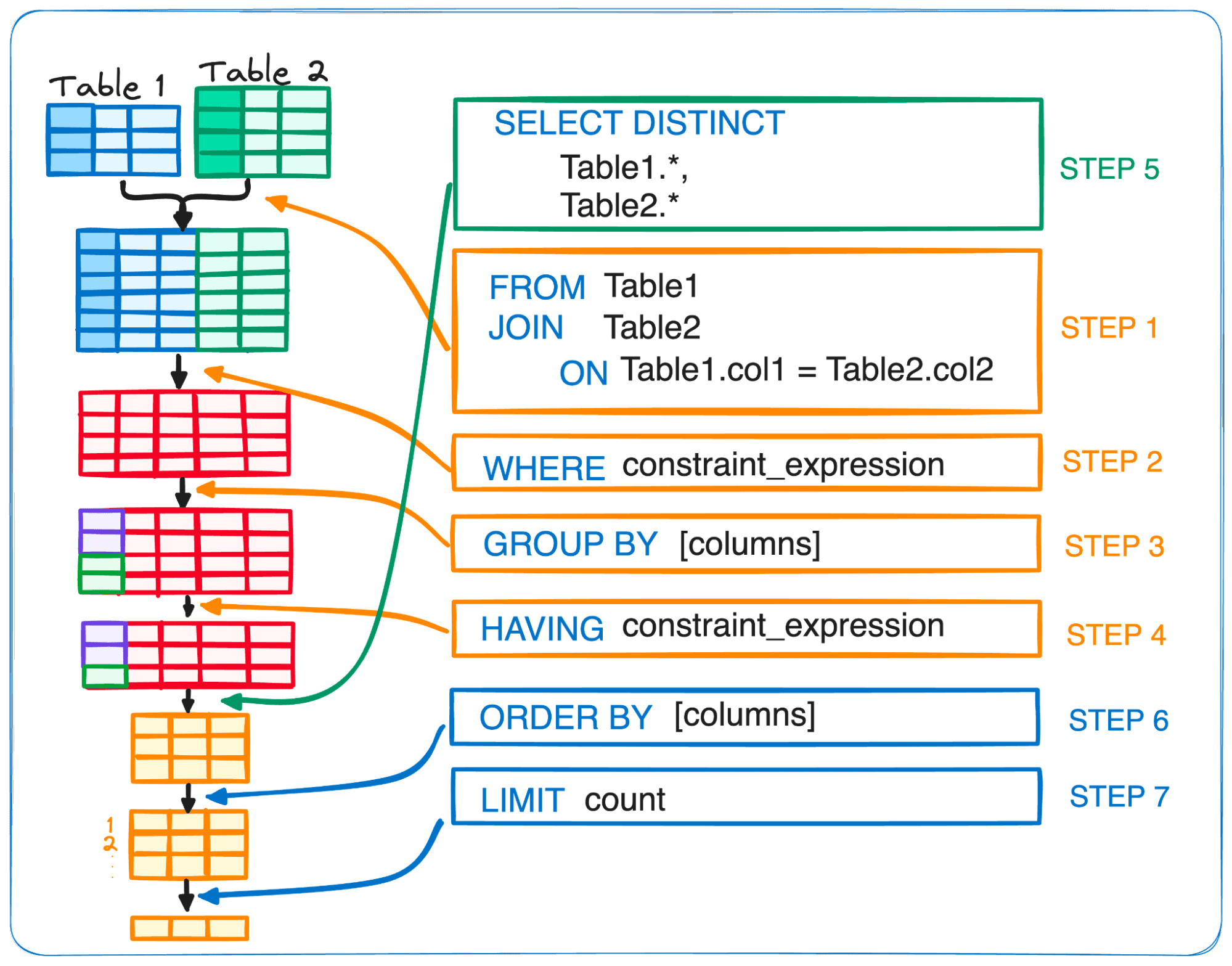
SELECT DISTINCT <select_list> FROM <left_table> <join_type> JOIN <right_table> ON <join_condition> WHERE <where_condition> GROUP BY <group_by_list> HAVING <having_condition> ORDER BY <order_by_condition> LIMIT <limit_number>
-
机读
FROM <left_table> ON <join_condition> <join_type> JOIN <right_table> WHERE <where_condition> GROUP BY <group_by_list> HAVING <having_condition> SELECT DISTINCT <select_list> ORDER BY <order_by_condition> LIMIT <limit_number>
-
总结
CREATE TABLE `tbl_dept` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`deptName` VARCHAR(30) DEFAULT NULL,
`locAdd` VARCHAR(40) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=INNODB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
CREATE TABLE `tbl_emp` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`name` VARCHAR(20) DEFAULT NULL,
`deptId` INT(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `fk_dept_id` (`deptId`)
#CONSTRAINT `fk_dept_id` FOREIGN KEY (`deptId`) REFERENCES `tbl_dept` (`id`)
) ENGINE=INNODB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
INSERT INTO tbl_dept(deptName,locAdd) VALUES('RD',11);
INSERT INTO tbl_dept(deptName,locAdd) VALUES('HR',12);
INSERT INTO tbl_dept(deptName,locAdd) VALUES('MK',13);
INSERT INTO tbl_dept(deptName,locAdd) VALUES('MIS',14);
INSERT INTO tbl_dept(deptName,locAdd) VALUES('FD',15);
INSERT INTO tbl_emp(NAME,deptId) VALUES('z3',1);
INSERT INTO tbl_emp(NAME,deptId) VALUES('z4',1);
INSERT INTO tbl_emp(NAME,deptId) VALUES('z5',1);
INSERT INTO tbl_emp(NAME,deptId) VALUES('w5',2);
INSERT INTO tbl_emp(NAME,deptId) VALUES('w6',2);
INSERT INTO tbl_emp(NAME,deptId) VALUES('s7',3);
INSERT INTO tbl_emp(NAME,deptId) VALUES('s8',4);
INSERT INTO tbl_emp(NAME,deptId) VALUES('s9',51);
-
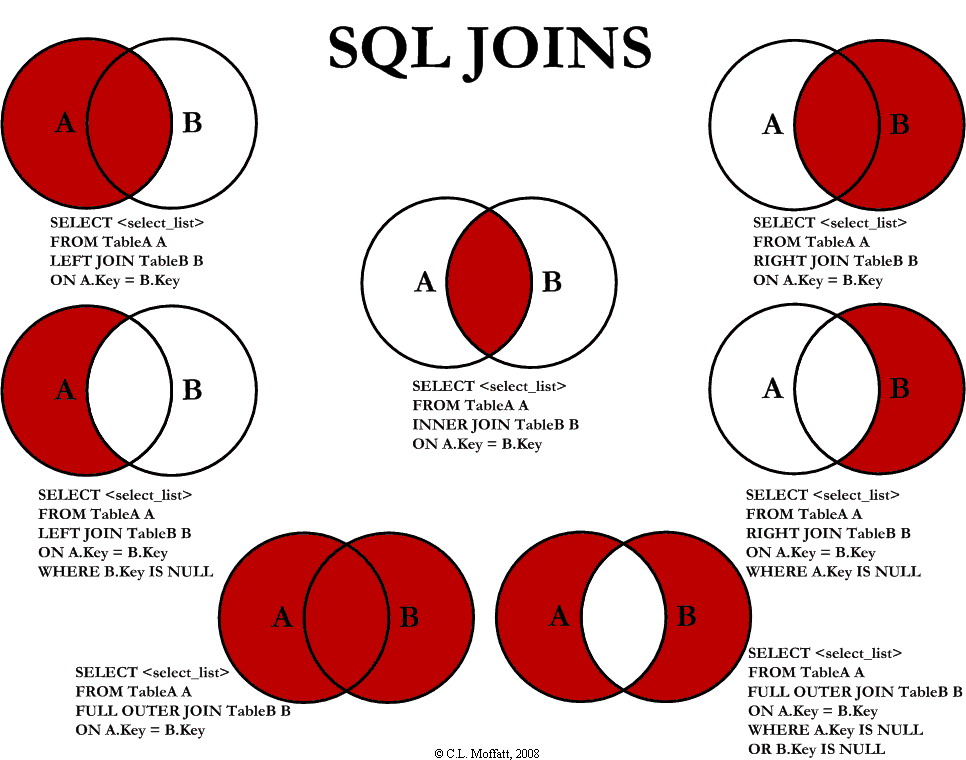
A、B两表共有
select * from tbl_emp a **inner join** tbl_dept b on a.deptId = b.id;
-
A、B两表共有+A的独有
select * from tbl_emp a **left join** tbl_dept b on a.deptId = b.id;
-
A、B两表共有+B的独有
select * from tbl_emp a **right join** tbl_dept b on a.deptId = b.id;
-
A的独有
select * from tbl_emp a left join tbl_dept b on a.deptId = b.id where b.id is null;
-
B的独有
select * from tbl_emp a right join tbl_dept b on a.deptId = b.id where a.deptId is null;
-
AB全有
MySQL Full Join的实现 因为MySQL不支持FULL JOIN,替代方法:left join + union(可去除重复数据)+ right join
SELECT * FROM tbl_emp A LEFT JOIN tbl_dept B ON A.deptId = B.id
UNION
SELECT * FROM tbl_emp A RIGHT JOIN tbl_dept B ON A.deptId = B.id-
A的独有+B的独有
SELECT * FROM tbl_emp A LEFT JOIN tbl_dept B ON A.deptId = B.id WHERE B.`id` IS NULL UNION SELECT * FROM tbl_emp A RIGHT JOIN tbl_dept B ON A.deptId = B.id WHERE A.`deptId` IS NULL;
count() 是一个聚合函数,对于返回的结果集,一行行地判断,如果 count 函数的参数不是 NULL,累计值就加 1,否则不加。最后返回累计值。
你首先要明确的是,在不同的 MySQL 引擎中,count(*) 有不同的实现方式。
- MyISAM 引擎把一个表的总行数存在了磁盘上,因此执行 count(*) 的时候会直接返回这个数,效率很高;
- 而 InnoDB 引擎就麻烦了,它执行 count(*) 的时候,需要把数据一行一行地从引擎里面读出来,然后累积计数。
那为什么 InnoDB 不跟 MyISAM 一样,也把数字存起来呢?
这是因为即使是在同一个时刻的多个查询,由于多版本并发控制(MVCC)的原因,InnoDB 表“应该返回多少行”也是不确定的。
对于 count(主键 id) 来说,InnoDB 引擎会遍历整张表,把每一行的 id 值都取出来,返回给 server 层。server 层拿到 id 后,判断是不可能为空的,就按行累加。
对于 count(1) 来说,InnoDB 引擎遍历整张表,但不取值。server 层对于返回的每一行,放一个数字“1”进去,判断是不可能为空的,按行累加。
单看这两个用法的差别的话,你能对比出来,count(1) 执行得要比 count(主键 id) 快。因为从引擎返回 id 会涉及到解析数据行,以及拷贝字段值的操作。
对于 count(字段) 来说:
- 如果这个“字段”是定义为 not null 的话,一行行地从记录里面读出这个字段,判断不能为 null,按行累加;
- 如果这个“字段”定义允许为 null,那么执行的时候,判断到有可能是 null,还要把值取出来再判断一下,不是 null 才累加。
按照效率排序的话,count(字段)<count(主键 id)<count(1)≈count(*),所以我建议你,尽量使用 count(*)